Structured data by default in open source library systems
The web
A platform for efficiently sharing cats

Also, hypertext documents
<html>
<head>
<title>Fancy academic article</title>
</head>
<body>
<h1>The web as intellectual rising tide</h1>
<p>As my esteemed colleague
<a href="http://example.com/author">Foo Bar</a> has
<a href="http://example.com/article">astutely observed</a>
...
</p>
<body>
</html>
Organizing the web Yahoo-style
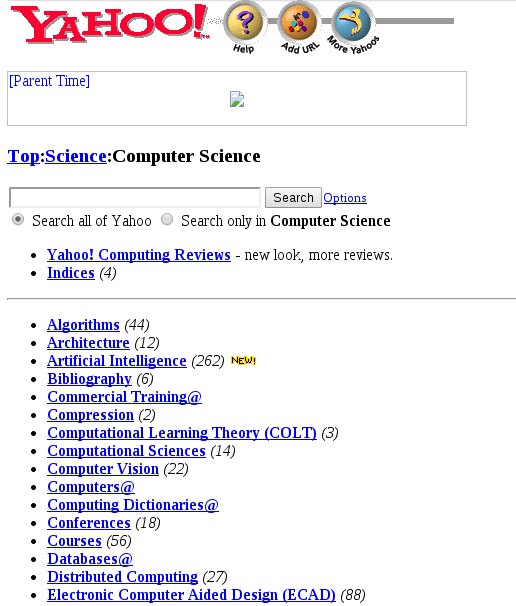
Internet Archive Wayback Machine
Organizing the web Yahoo-style
Yahoo's architecture provides a fairly consistent and easy to use interface for browsing a hierarchy of roughly 70,000 entries. [...]Rosenfeld, Lou. CMC Magazine, "The Untimely Death of Yahoo". September 1, 1995. (online)
Due to this ambiguity [of keyword searching], information searching is just plain hard, regardless of whether you're dealing with Yahoo's index or the card catalog at your local public library. [...]
Google: ranking the link (and more)
Google attacked the bag of words keyword problem a number of ways:
- PageRank algorithm - evolution of academic citation analysis
- Weighting keyword importance by appearance (size, boldness)
- Using keywords in external links to a given page
... and won (at least to date)
Bags of words are still hard
Plenty of ambiguity problems remain
- When a web page mentions "Dan Scott", it could be:
- the character from the One Tree Hill TV show
- the artist from Magic the Gathering card game
- the Ontario academic professor from the University of Waterloo
- the Ontario academic librarian from Laurentian University
- What about variations like "Daniel B. Scott", "Scott, Dan", "Scott, Dan, 1972-"?
Vannevar Bush and the Memex
publication has been extended far beyond our present ability to make real use of the record.Atlantic Monthly, "As We May Think". July 1, 1945.
[...]
A record if it is to be useful to science, must be continuously extended, it must be stored, and above all it must be consulted.
Tim Berners-Lee and the Web
HTTP and HTML enter the scene:
We should work toward a universal linked information system, in which generality and portability are more important than fancy graphics techniques and complex extra facilities.CERN. "Information Management: A Proposal". May 1990.
Tim Berners-Lee and the Semantic Web
The Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation.Scientific American, "The Semantic Web". May 17, 2001.
Tim Berners-Lee and Linked Data
for HTML or RDF, the same expectations apply to make the web grow:Berners-Lee, Tim. "Linked data - design issues". July 27, 2006.
- Use URIs as names for things
- Use HTTP URIs so that people can look up those names.
- When someone looks up a URI, provide useful information, using the standards (RDF*, SPARQL)
- Include links to other URIs. so that they can discover more things.
Resource Description Framework (RDF) and XML
- RDF describes
subject::property::valuerelationships as triples - Linked data replaces literal values with URLs to support a graph structure
- Common early serialization of RDF triples was in XML:
W3C. "RDF/XML Syntax Specification (Revised)". February 10, 2004. Online<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:ex="http://example.org/stuff/1.0/"> <rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar" dc:title="RDF/XML Syntax Specification (Revised)"> <ex:editor> <rdf:Description ex:fullName="Dave Beckett"> <ex:homePage rdf:resource="http://purl.org/net/dajobe/" /> </rdf:Description> </ex:editor> </rdf:Description> </rdf:RDF>
RDF in Attributes (RDFa)
- RDF serialization that uses a handful of attributes to decorate existing XML
- Proposed in 2004 for use in XHTML; started to take off with HTML5
<body vocab="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
prefix="dc: http://purl.org/dc/elements/1.1/
ex: http://example.org/stuff/1.0/">
<div typeof="Description"
about="http://www.w3.org/TR/rdf-syntax-grammar">
<h1 property="dc:title">RDF/XML Syntax Specification (Revised)</h1>
<div property="ex:editor" typeof="Description">
<span property="ex:fullName">
<a href="http://purl.org/net/dajobe/"
property="ex:homePage">Dave Beckett</a>
</span>
</div>
</div>
</body>The Semantic Web circa 2010
- Semantic Web efforts resulted in many deeply specialized vocabularies (objects and properties)
-
- Best practice was to mix and match vocabularies
- Web Ontology Language (OWL) enables subtle cross-vocabulary equivalence expressions
- Despite linked data principles, still highly complex and easily overwhelming
- Content negotiation for different serializations (RDF/XML, N3, Turtle, ...): difficult in practice to deploy
- Competing practitioner approaches included microformats, structured data via microdata and RDFa, OGP
- Result was academically interesting, but in many ways a heterogenous mess
schema.org
- In July 2011, schema.org was announced by major search engines (Google, Yahoo, Yandex)
- Some goals:
- Offer a simple vocabulary for the short tail of web results (events, products, people)
- Enable normal web page publishers to be able to add schema.org markup via RDFa or microdata without having to be Semantic Web experts
- Enable search engines to aggregate data and apply finer-grained disambiguation and relevance strategies
Libraries: early technology adopters
- Telnet access to catalogues
- Z39.50 protocol for sharing records
- OpenURL protocol for resolving article requests
- COinS microformat for embedding citations in HTML
- unAPI for offering different metadata representations
Fatal flaw: almost entirely library-specific technologies
MARC: (still) kind of a big deal
... to libraries ...

Enduring technology
MAchine Readable Cataloging (MARC)
- Binary format designed for record sharing and tape storage in the 1960s
- Mixture of position-dependent data in "fixed fields" and fields with variable-length subfields
- Combined with cataloging rules to create conventions like:
245 $a $b $c = Title
02199cam a22004698i 4500
001 123456
005 20131223124722.0
008 130924s2013 nyu b 001 0 eng
020 $a 9780804139571
100 1 $a Burgundy, Ron
245 10 $a Let me off at the top! $b my classy life and other musings
264 1 $a New York : $b Crown Archetype, $c [2013].
300 $a 223 pages, 16 unnumbered pages of plates : $b illustrations ; $c 22 cm
MARC: XML serialization
Same inscrutable semantics, more verbose, but usable with standard tools
02199cam a22004698i 4500
123456
20131223124722.0
130924s2013 nyu b 001 0 eng
9780804139571
Burgundy, Ron.
Let me off at the top!
my classy life and other musings
MARC is still at the core of almost every library system today
Linked data library systems
- Some library systems have successfully discarded MARC in favour of a linked data model:
- Swedish Union Catalog
- German National Library
- Bibliothèque nationale de France
- Common attributes:
- Large institutions
- Resources to sustain multi-year development efforts with concurrent systems
- Ability to mandate significant changes to established practices
- Not a model that can be followed by most resource-constrained libraries today
Research directions
- Questions:
- Can library systems evolve towards a linked data model?
- Can library metadata be relevant to normal search engines?
- Actions:
- Map MARC data to schema.org vocabulary
- Implement schema.org in open source library systems
- Propose enhancements to schema.org for library and bibliographic data
- Propose enhancements to MARC standards to support evolution towards linked data models
MARC data to schema.org base types
| Schema.org type | MARC 21 leader[06] value |
|---|---|
| Book | a |
| Map | e |
| MusicAlbum | j |
| CreativeWork | All other leader values |
MARC to schema.org properties
| Schema.org property | MARC 21 field/subfield |
|---|---|
name |
245/All subfields except w, 0, 4, 5, 6, 8, 9 |
Book :: isbn |
022/a |
publisher :: Organization :: location |
(260/a or 264[indicator 2="1"])/a |
publisher :: Organization :: name |
(260/b or 264[indicator 2="1"])/b |
datePublished |
(260/c or 264[indicator 2="1"])/c |
(Just a small sample)
Library items as schema.org Offers
- GoodRelations vocabulary for surfacing product information, based on an agent-object-promise model, was incorporated into schema.org
- Library-specific holdings vocabulary seemed unlikely to gain traction from search
- Libraries offer items for "lease" at zero cost (W3 Schema.org Bibliographic Extension community group recommended practice)
- Potential to disintermediate the relationship between libraries and search engines
| Offer property | Library item |
|---|---|
seller | Library |
sku | Call number |
serialNumber | Barcode |
availableAtOrFrom | Shelving location |
availability | Item status |
2012 Common Crawl analysis
- Ronallo(*) found that American academic libraries published under 10,000 schema.org instances in total
- Possible reasons for this low adoption rate include:
- Perceived return on investment is low in risk-averse, under-resourced institutions
- Proprietary systems do not facilitate shared modifications of HTML templates
- Sufficient access to underlying metadata may not be available in proprietary systems
Open source library systems
the modifications [can] be done by those actors who have the best information about their value [and] are best equipped to carry them outSchwarz, M., Takhteyev, Y.: Half a Century of Public Software Institutions: Open Source as a Solution to HoldUp Problem. Journal of Public Economic Theory. 12(4), 609–639 (2010)
- Open source library systems can evolve quickly:
- Contributions from a broad community adopted and released on a rapid, iterative cycle
- "Power of the default" means that those who upgrade to the latest release usually reflect default settings
- Hypothesis: Open source library systems are most likely to contribute schema.org linked data in the short term
Open source implementations
- My efforts have:
- Enhanced Evergreen, Koha, and VuFind to publish schema.org data
- Enhanced Evergreen to expose
Librarymetadata (location, contact information, hours of operation) linked from offers
- Independently, the Blacklight library system was enhanced to publish schema.org data
- Open source moves very fast: Koha already deprecated the theme I enhanced
- Approximately 4,000 library systems will publish schema.org data as sites adopt the latest releases
- Plan: Once a Common Crawl 2014 corpus is available, rerun Ronallo's analysis and determine sources of schema.org data
Quick union catalogues
- Many libraries have resource-sharing agreements, but infrastructure requires crufty Z39.50 lookups or periodic MARC batch loads
- Promise: A common vocabulary and mapping practices should ease cross-system integration
- Use case: Google Custom Search Engine (CSE) supports facets based on structured data such as schema.org
- Result: It works!
- Combined Evergreen + VuFind instances in a single search instance
- Faceted by schema.org
authorvalue - Exposes Google's simplistic string-based implementation of structured data
- Plan: Implement a custom search engine that periodically crawls sitemaps, understands complex RDF, and can look up availability in real time
Extending the schema.org vocabulary
- schema.org had an
Articletype and an unstructuredcitationproperty - Initial focus on online information had made it impossible to represent a significant part of the world's information
- Drove a
Periodicalextension proposal that supported journal/magazine relationships:Article:: isPartOf :: PublicationIssue:: isPartOf :: PublicationVolume:: isPartOf :: Periodical
- Enables structured inline citations, regardless of citation format!
Summary
- W3C standardization process can be daunting, but works
- Open source software as reference implementation:
- Strengthens proposals
- May hasten proprietary implementations
- Benefits the world!
- Much more to do:
- Common Crawl analyses: broaden domains for 2012, update for 2014
- Build a proof-of-concept RDFa crawler / extractor union catalogue
- Port Koha effort to latest theme
- Improve type mapping (diving into fixed fields)
- Evolve MARC towards directly linked data