Structuring library data on the web with schema.org
One day at Google I/O 2012...
Ade Oshineye was singing the praises of Google+ Local pages
Some guy commented on Ade's G+ post about the presentation:
Still looking forward to a simple solution for automated Page updates for non-spammy metadata like hours of operation (yes, I was the guy who asked that question). Maybe we could teach G+ to scrape some selected microdata from an authoritative linked Web site, if pushing seems too dangerous?
The trouble with the web
Happy 25th, World Wide Web!
We should work toward a universal linked information system, in which generality and portability are more important than fancy graphics techniques and complex extra facilities. [...] There is also much support from the publishing industry, and from librarians whose job it is to organise information.
CERN. "Information Management: A Proposal". March 1989.
A platform for efficiently sharing cats

Also, hypertext documents
<html>
<head>
<title>Fancy academic article</title>
</head>
<body>
<h1>The web as intellectual rising tide</h1>
<p>As my esteemed colleague
<a href="http://example.com/author">Foo Bar</a> has
<a href="http://example.com/article">astutely observed</a>
...
</p>
</body>
</html>
Organizing the web Yahoo-style
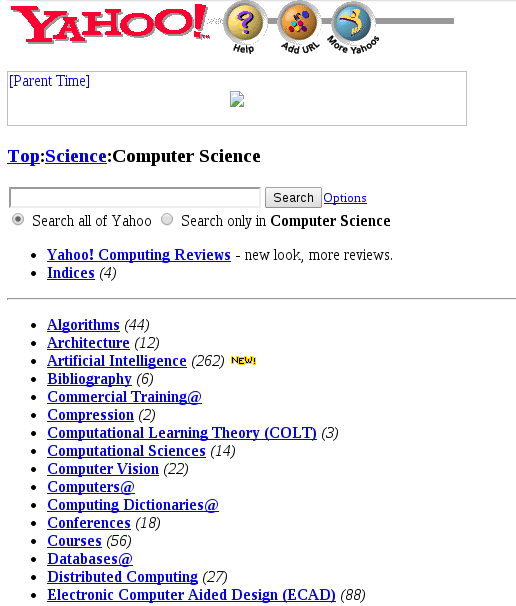
Organizing the web Yahoo-style
Yahoo's architecture provides a fairly consistent and easy to use interface for browsing a hierarchy of roughly 70,000 entries. [...]Due to this ambiguity [of keyword searching], information searching is just plain hard, regardless of whether you're dealing with Yahoo's index or the card catalog at your local public library. [...]
Rosenfeld, Lou. September 1, 1995. (online)
Google and the bag of words
- PageRank algorithm - evolving academic citation analysis
- Weighting keyword importance by appearance (size, boldness)
- Using keywords in external links to a given page
Bags of words are still hard
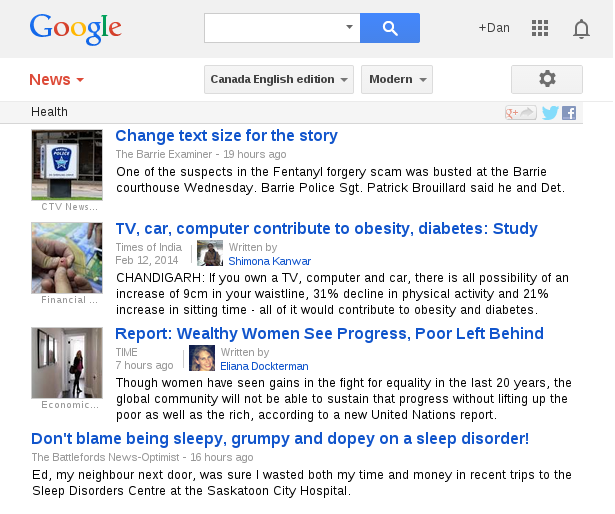
Bags of words are still hard
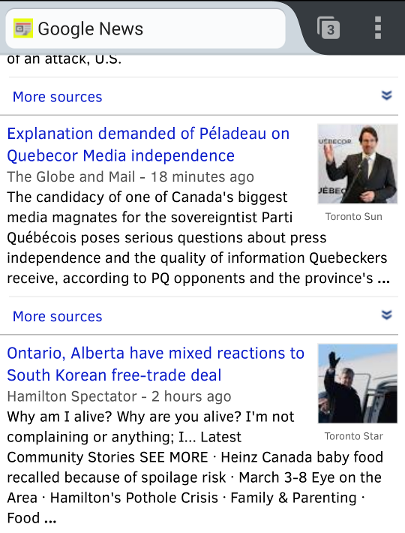
Plenty of ambiguity problems remain
- When a web page mentions "Dan Scott", it could be:
- the character from the One Tree Hill TV show
- the artist from Magic the Gathering card game
- the Ontario academic professor from the University of Waterloo
- the Ontario academic librarian from Laurentian University
- What about variations like "Daniel B. Scott", "Scott, Dan", "Scott, Dan, 1972-"?
Trouble with the Semantic Web
Tim Berners-Lee again
The Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation.
Scientific American, "The Semantic Web". May 17, 2001.
Tim Berners-Lee and Linked Data
for HTML or RDF, the same expectations apply to make the web grow:
- Use URIs as names for things
- Use HTTP URIs so that people can look up those names.
- When someone looks up a URI, provide useful information, using the standards (RDF*, SPARQL)
- Include links to other URIs. so that they can discover more things.
Berners-Lee, Tim. "Linked data - design issues". July 27, 2006.
Resource Description Framework (RDF)
- RDF describes
subject::property::valuerelationships as triples - Linked data replaces literal values with URLs to support a graph structure
- Common early serialization of RDF triples was in XML:
<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:ex="http://example.org/stuff/1.0/"> <rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar" dc:title="RDF/XML Syntax Specification (Revised)"> <ex:editor> <rdf:Description ex:fullName="Dave Beckett"> <ex:homePage rdf:resource="http://purl.org/net/dajobe/" /> </rdf:Description> </ex:editor> </rdf:Description> </rdf:RDF>W3C. "RDF/XML Syntax Specification (Revised)". February 10, 2004. Online
The Semantic Web circa 2010
- Semantic Web efforts resulted in many deeply specialized vocabularies (objects and properties)
-
- Best practice was to mix and match vocabularies
- Web Ontology Language (OWL) enables subtle cross-vocabulary equivalence expressions
- Despite linked data principles, still highly complex and easily overwhelming
- Content negotiation for different serializations (RDF/XML, N3, Turtle, ...): difficult in practice to deploy
- Competing practitioner approaches included microformats, structured data via microdata and RDFa, OGP
- Result was academically interesting, but in many ways a heterogenous mess
RDF in Attributes (RDFa)
- RDF serialization that uses a handful of attributes to decorate existing XML
- Proposed in 2004 for use in XHTML; started to take off with HTML5
<html>
<head><title>Fancy academic article</title></head>
<body vocab="http://schema.org/" typeof="ScholarlyArticle">
<h1 property="name">The web as intellectual rising tide</h1>
<div property="articleBody">
<p>As my esteemed colleague
<a href="http://example.com/author" typeof="Person">Foo Bar</a> has
<a href="http://example.com/article" property="citation">astutely observed</a>
...
</p>
</div>
</body>
</html>schema.org
schema.org
- In July 2011, schema.org was announced by major search engines (Google, Yahoo, Yandex)
- Some goals:
- Offer a simple vocabulary for the short tail of web results (events, products, people)
- Enable normal web page publishers to be able to add schema.org markup via RDFa Lite or microdata without having to be Semantic Web experts
- Enable search engines to aggregate data and apply finer-grained disambiguation and relevance strategies
- A reaction to the state of the Semantic Web
schema.org: hierarchical types
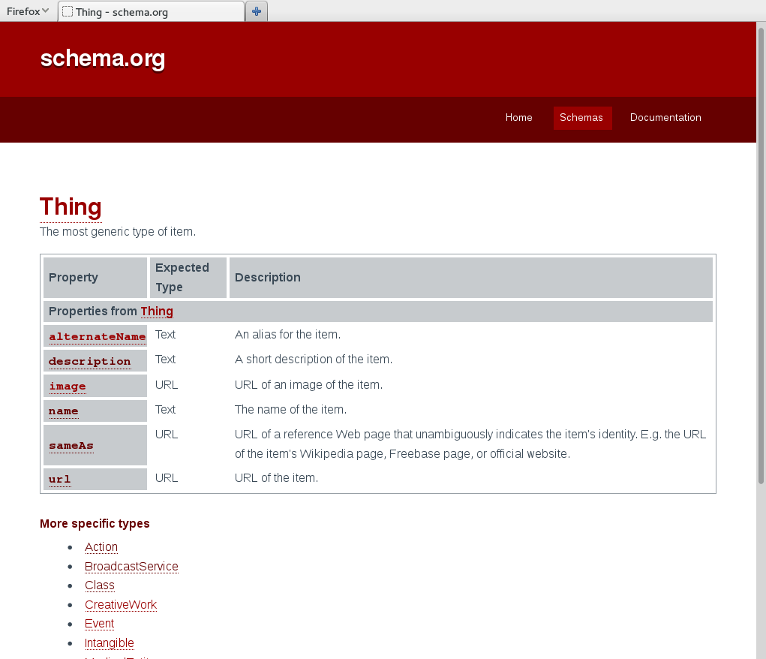
schema.org: Creative Works
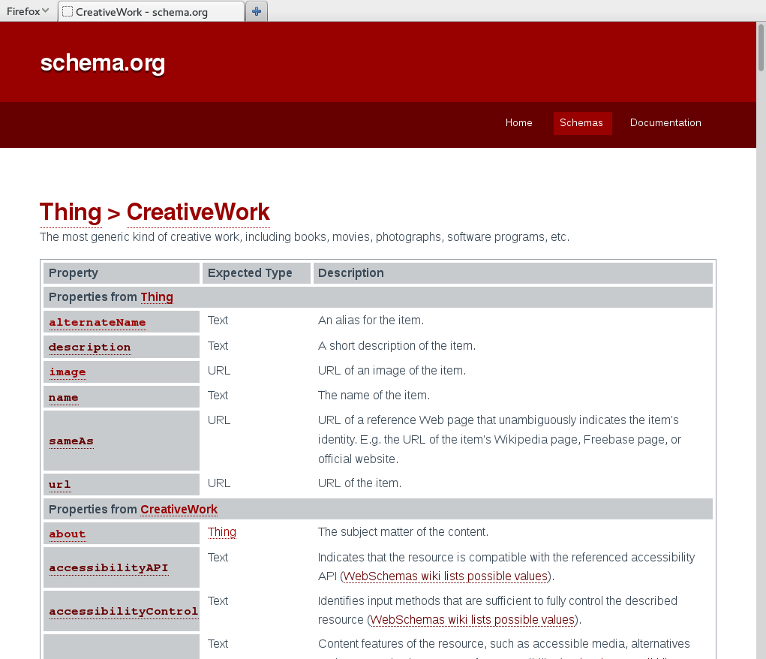
schema.org: focus on examples
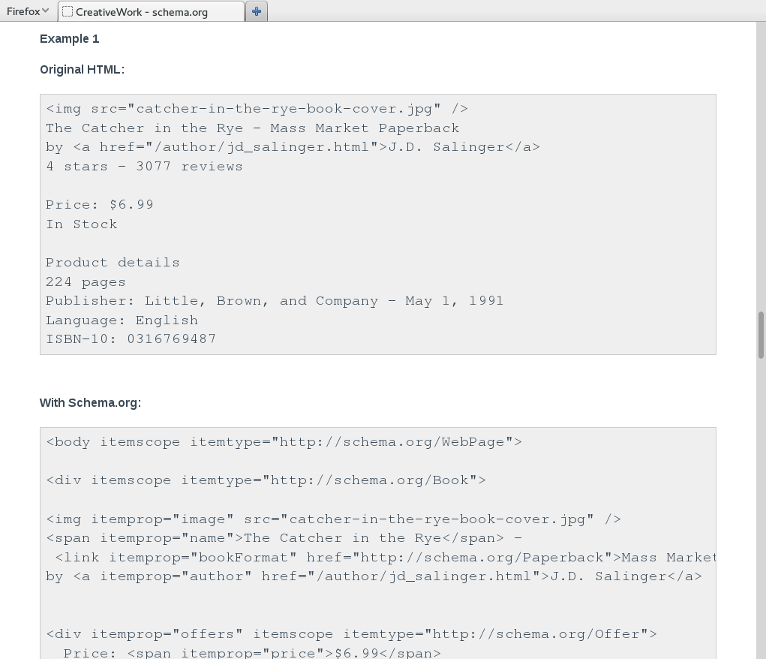
Libraries: early technology adopters
- Telnet access to catalogues
- Z39.50 protocol for sharing records
- OpenURL protocol for resolving article requests
- COinS microformat for embedding citations in HTML
- unAPI for offering different metadata representations
Consistent flaw: almost entirely library-specific technologies
MARC: (still) kind of a big deal

Enduring technology
MAchine Readable Cataloging (MARC)
02199cam a22004698i 4500
001 123456
005 20131223124722.0
008 130924s2013 nyu b 001 0 eng
020 $a 9780804139571
100 1 $a Burgundy, Ron
245 10 $a Let me off at the top! $b my classy life and other musings
264 1 $a New York : $b Crown Archetype, $c [2013].
300 $a 223 pages, 16 unnumbered pages of plates : $b illustrations ; $c 22 cm
MARC: XML serialization
Same inscrutable semantics, more verbose, but usable with standard tools
02199cam a22004698i 4500
123456
20131223124722.0
130924s2013 nyu b 001 0 eng
9780804139571
Burgundy, Ron.
Let me off at the top!
my classy life and other musings
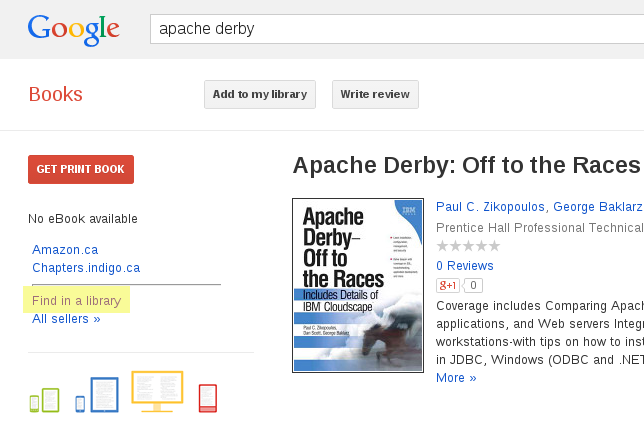
If your holdings are not in OCLC, you're not linked to Google Books.
Our decentralized infrastructure has been centralized.
Linked data library system leadership
- Some library systems have supplemented or discarded MARC for a linked data model:
- Swedish Union Catalog
- German National Library
- Bibliothèque nationale de France
But is your library...
- Large (national scale)
- Able to sustain multi-year development efforts with concurrent systems
- Able to mandate significant changes to established practices
- ...?
Better living through Web standards
Better living through Web standards
- Hypothesis: We can iterate towards linked data with existing systems
- Enhance our catalogues with web standards:
- Persistent URIs
- HTML5
- RDFa (or microdata) expressing schema.org
- Sitemaps listing all the URIs of interest
Reality check: 2012 Common Crawl
- Ronallo(*) found that American academic libraries published under 10,000 schema.org instances in total
- Possible reasons for this low adoption rate include:
- Perceived return on investment is low in risk-averse, under-resourced institutions
- Proprietary systems do not facilitate shared modifications of HTML templates
- Sufficient access to underlying metadata may not be available in proprietary systems
Open source library systems
the modifications [can] be done by those actors who have the best information about their value [and] are best equipped to carry them out
Schwarz, M., Takhteyev, Y. (2010)
- Open source library systems can evolve quickly:
- Contributions from a broad community adopted and released on a rapid, iterative cycle
- "Power of the default" means that those who upgrade to the latest release usually reflect default settings
- Hypothesis: Open source library systems are most likely to contribute schema.org linked data in the short term
Open source implementations
- My efforts have, in the spirit of Dorothea Salo's Linked data in the creases:
- Enhanced Evergreen, Koha, and VuFind to publish schema.org data
- Enhanced Evergreen to expose
Librarymetadata (location, contact information, hours of operation) linked from offers
- Independently, the Blacklight library system was enhanced to publish schema.org data
- Approximately 4,000 library systems will publish schema.org data as sites adopt the latest releases
We're all in this together: SchemaBibEx
The mission of this group is to discuss and prepare proposal(s) for extending Schema.org schemas for the improved representation of bibliographic information markup and sharing.
- Founded by Richard Wallis (OCLC) in September 2012, participants include Karen Coyle, Niklas Lindstrom
- Formally known as the W3C Schema Bib Extend community group
- Accomplishments include:
- Citations as properties of all CreativeWorks (accepted)
- Holdings as expressions of Offers (best practice)
- Collections for complex relationships between CreativeWorks (proposed)
- Periodicals as containers for Articles (proposed)
SchemaBibEx: Citations everywhere
- Originally only the
MedicalScholarlyArticletype had acitationproperty - Alf Eaton, via SchemaBibEx, proposed making the property applicable to all
CreativeWorktypes - Status: accepted

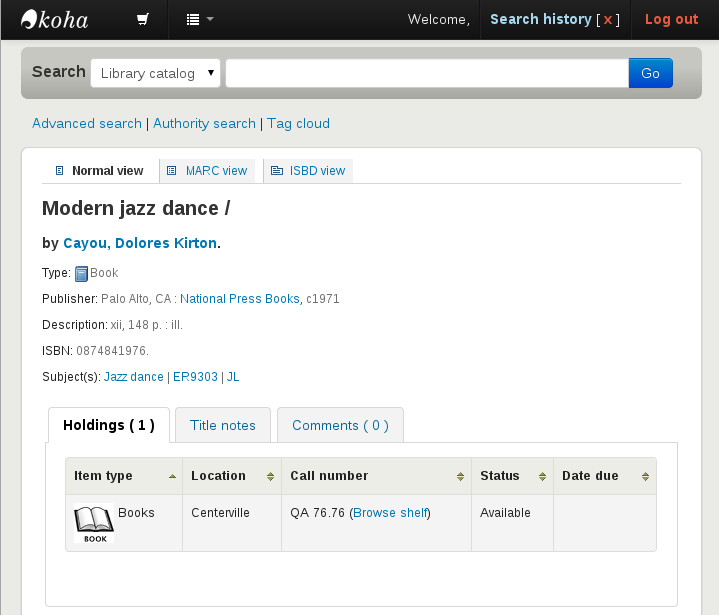
SchemaBibEx: Library items as schema.org Offers
- GoodRelations vocabulary for surfacing product information, based on an agent-object-promise model, was incorporated into schema.org
- Library-specific holdings vocabulary seemed unlikely to gain traction from search engines
- Libraries therefore offer items for "lease" at zero cost
- Status: SchemaBibEx recommended practice
Mapping holdings to schema.org Offers
| Offer property | Library item |
|---|---|
seller | Library |
sku | Call number |
serialNumber | Barcode |
availableAtOrFrom | Shelving location |
availability | Item status |
Holdings as Offers: example
<tr property="offers" typeof="Offer">
<td>
<a property="seller" typeof="Library" href="http://example.org/library">
<span property="name">C.H. Booth Library - Newtown</span>
</a>
<link property="businessFunction" href="http://purl.org/goodrelations/v1#LeaseOut">
<link property="itemOffered" href="#schemarecord">
</td>
<td><span property="sku">641.5 ROM c. 2</span></td>
<td property="serialNumber">34014012862984</td>
<td property="availableAtOrFrom">Adult Nonfiction</td>
<td><link property="availability" href="http://schema.org/InStock">Available</td>
</tr>
SchemaBibEx: Periodicals
- schema.org had an
Articletype and an unstructuredcitationproperty - Focus on online access overlooked relationships to publications and print attributes
- Drove a
Periodicalextension proposal that supported journal/magazine relationships:Article(and all child types such asScholarlyArticle):: isPartOf :: PublicationIssue:: isPartOf :: PublicationVolume:: isPartOf :: Periodical:: isPartOf :: Book
- Enables structured inline citations, regardless of citation format!
- Status: Under consideration by schema.org
SchemaBibEx: Comics
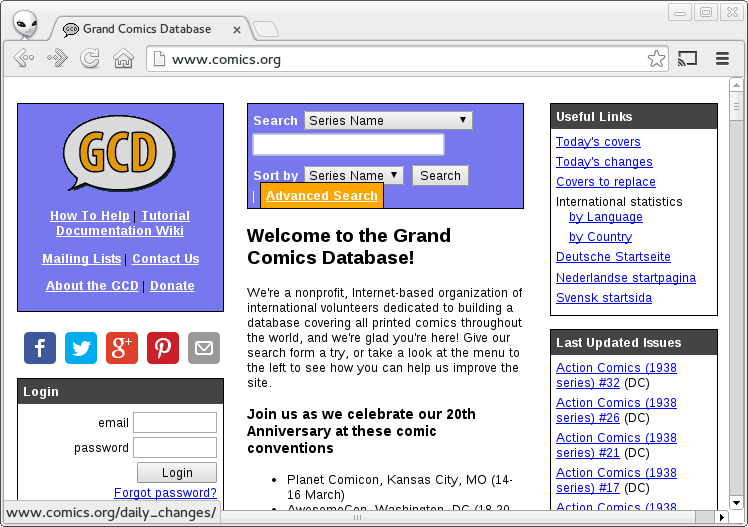
SchemaBibEx: Comics
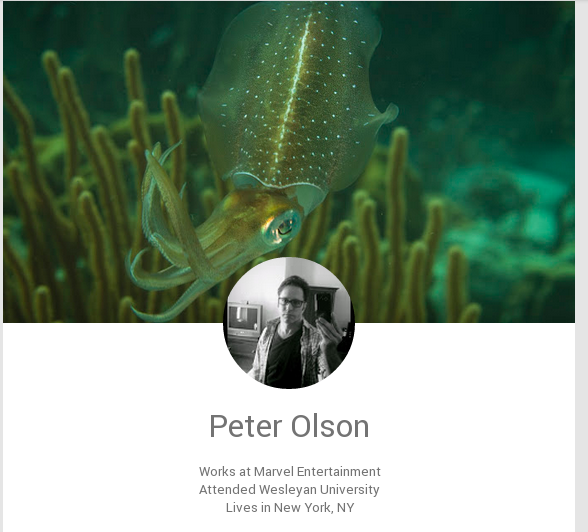
SchemaBibEx: Comics
- Collaborating with Henry Andrews (comics.org) and Peter Olson (Marvel)
- Specialization of
Periodical - Depends on outcome of contributor/role discussion for
SportsEventproposal - Status: In progress
SchemaBibEx: overall status
- Exited active extension proposal development mode
- Documenting best practices and supporting adopters
- Will call ad-hoc meetings for new extension requirements
- Join our community and post questions to the mailing list!
Structured library information
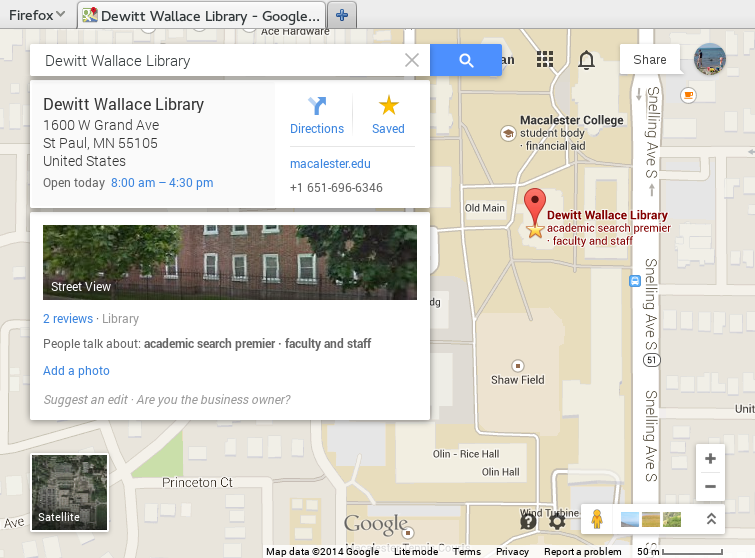
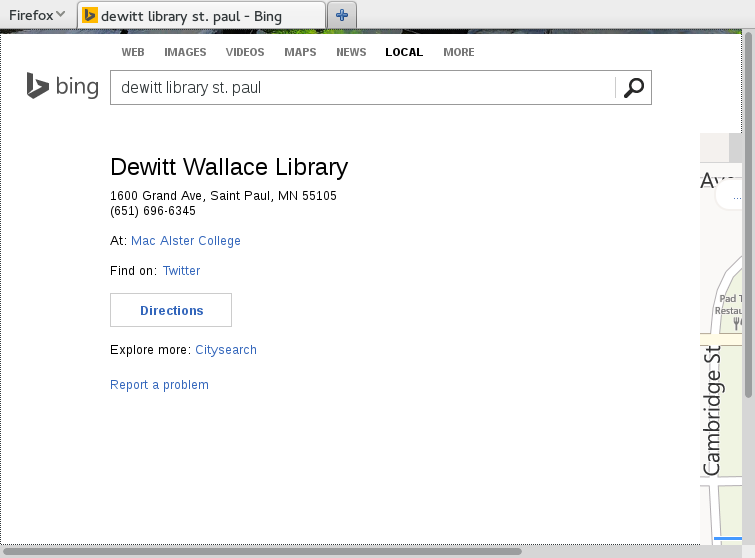
Structured library information
- schema.org offers a
Libraryorganization type - ILS often tracks library hours, contact information, address, branch relationships
- Evergreen, as of 2.6 release, will expose this information by default
- You should not have to maintain business pages in umpteen different social networks!
Structured library information example
<div vocab="http://schema.org/" typeof="Library">
<h1 property="name">Example Branch 1</h1>
<div><a href="http://example.com/BR1" property="url">Library web site</a></div>
<h2>Opening hours</h2>
<div property="openingHoursSpecification" typeof="OpeningHoursSpecification">
<link property="dayOfWeek" href="http://purl.org/goodrelations/v1#Monday">
Monday: <span property="opens">12:00 AM</span> -
<span property="closes">12:00 AM</span>
</div>
<h2>Contact information</h2>
<div>Email: <a href="mailto:br1@example.com" property="email">br1@example.com</a></div>
<div>Telephone: <a href="tel:(555) 555-0271" property="telephone">(555) 555-0271</a></div>
<div property="location address" typeof="PostalAddress">
<h3 property="contactType">Mailing address</h3>
<span property="streetAddress">BR1<br>123 Main St.</span><br>
<span property="addressLocality">Anywhere</span><br>
<span property="addressRegion">GA</span><br>
<span property="addressCountry">US</span><br>
<span property="postalCode">30303</span><br>
</div>
<h2>Branch relationship</h2>
<div id="branch-info">Parent library:
<a property="branchOf" href="/eg/opac/library/SYS1">Example System 1</a>
</div>
Thought experiment
- So we're exposing our holdings to the web...
- in a common format understood by search engines...
- linked to the library that holds the items...
- with that library's physical address, hours of operation, web site and contact info...
- ...
- when can we stop doing batch uploads to OCLC and/or other union catalogues?
Sitemaps
- Standard documented at http://sitemaps.org
- Simple XML lists of URLs that should be crawled, with optional change information:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://laurentian.concat.ca/eg/opac/record/100000?locg=105</loc>
<lastmod>2009-05-03</lastmod>
</url>
<url>
<loc>http://laurentian.concat.ca/eg/opac/record/100001?locg=105</loc>
<lastmod>2009-05-03</lastmod>
</url>
...
</urlset>
Quick union catalogues
- Many libraries have resource-sharing agreements, but infrastructure requires crufty Z39.50 lookups or periodic MARC batch loads
- Promise: Common vocabulary and mapping practices should ease cross-system integration
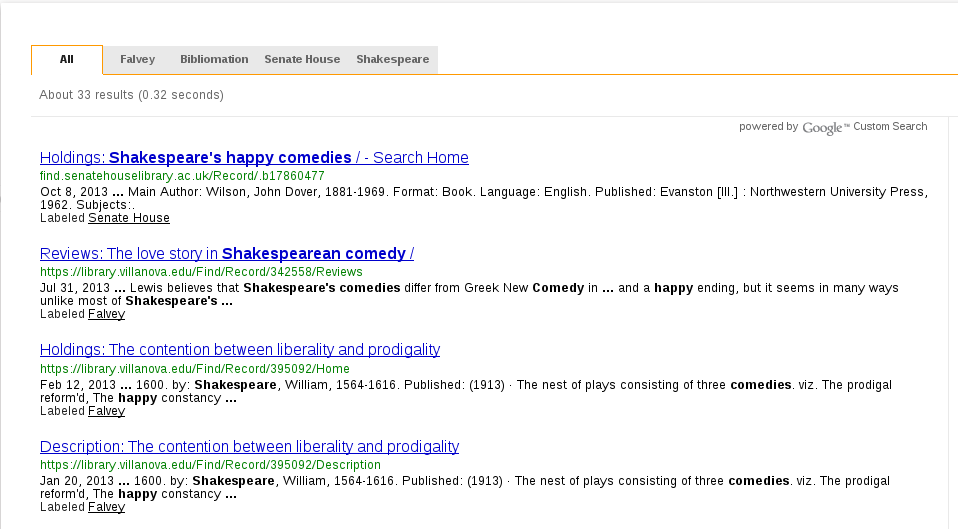
- Use case: Google Custom Search Engine (CSE) supports facets based on structured data such as schema.org
- Result: It works!
- Combined Evergreen + VuFind instances in a single search instance
- Faceted by schema.org
authorvalue - Exposes Google's simplistic string-based implementation of structured data
Quick union catalogues: in progress
- Schema UnionCat: < 100 lines of Python to crawl sitemaps and extract complex RDF
- Currently a proof of concept
- Future enhancements (if there is interest):
- Only crawl new and updated sitemap entries
- Store and search extracted RDF
- Check item availability on demand
Summary
- Web standards (sitemaps, RDFa, schema.org) > library-niche solutions and offer a path back to decentralization
- Catalogues can feed metadata directly to general search engines
- Open source implementations strengthen proposals; may hasten and improve proprietary implementations
- We have much more to do:
- Common Crawl analyses: broaden domains for 2012, update for 2014
- Enhance proof-of-concept RDFa crawler / extractor / union catalogue
- Evolve MARC towards directly linked data
- SchemaBibEx now in
community support mode
; if you have implementation questions, ask us!
Resources
- RDFa Lite 1.1 W3C recommendation
- schema.org - official web site
- schema.org hands-on code lab - teaches you step by step how to add schema.org to a web page using RDFa
- W3C Schema Bib Extend Community Group - best practices for schema.org bibliographic use cases, extension proposals in progress, mailing list for assistance