
Short Topics
- XQuery: its Relationship to CQL
- OpenURL: Why can't it be used as a query syntax? (Why do we need SRU?)
- OAI, OpenURL, and sru: How might these three work together?
- SRU: Post Vs. Get
- OpenSearch Vs. SRU Parameter Names
- SRU vs. Z39.50
- What are the potential advantages of SRW over SRU?
- Federated Search
XQuery: Its Relationship to CQL
Query languages for the most part are either:
(a) powerful and expressive but complex and cryptic, not human-friendly;
or
(b) simple and easy to understand, user-friendly, but lacking in functionality.
Examples of (a) are W3C's XQuery, SQL, and the Z39.50 type-1 query. Examples of (b) are CCL and Google. Query languages in general do not combine functionality and user-friendliness; CQL is an attempt to combine these two features.
More to the point, CQL's goal is to combine the simplicity and intuitiveness of google searching with the expressive power of the Z39.50 query; to allow users to begin with very simple queries and work their way up to arbitrarily complex expressions as necessary.
For example, the following (valid) CQL queries are intuitive and need no explanation:
- birds
- birds or dinosaurs
- dinosaur not reptile
- dinosaur and bird or dinobird
- title= dinosaur and author=crichton
- (((a and b) or (c not d) not (e or f and g)) and h not i) or j
- publicationYear < 1980
- numberOfWheels <= 3
- numberOfToes <> 3
And the following are reasonably but not completely intuitive:
- birds prox dinosaurs -- "find birds near dinosaurs"
- birds proxprox/distance=1/unit=sentence dinosaurs -- "... . Within the same sentence"
- dc.title= dinosaur and bath.author=crichton -- "find dinosaur in the dc title index and crichton in the bath author index"
- author all "crichton michael" -- "author contains all of these words"
- author any "crichton michael" -- "author contains any of these words"
The second set of examples reflect more functionality that those in the first set and are correspondingly more complex, but not disproportionately so.
XQuery, on the other hand, is a large and complex specification, which has been in development for a long time (several years) and consists of a number of (12 or so) large documents. It is difficult to comprehend without committing several days to reading the documents. CQL, by contrast, can be understood completely in an hour or so.
The XQuery development has been influenced, almost entirely, by two very distinct constituencies: (1) XML-as-document and (2) XML-as-data. The first reflects XML's roots as SGML, while the second reflects a relational database bias. Neither of these constituencies "won"; XQuery, rather than defining different queries for the different models, attempts to meet the needs of both constituencies with a single language.
Both XQuery and CQL assume that information is returned as XML. But XQuery goes a step further. It assumes that the information to be queried is (or is representable as) XML; CQL makes no such assumption.
Both languages specify a non-xml syntax; XQuery, in addition, defines an alternative XML syntax.* In the XQuery case, this reflects apparent inability to resolve the question of whether an XML query syntax should itself be XML. Though on the surface it seems a good idea, the CQL developers ultimately decided it was not.
*(CQL did specify an alternative XML sytax, XCQL, in version 1.0, but abandoned it in 1.1. That is, it abandoned it for purposes of submitting the query. CQL retains the XCQL spec to be used by server to "echo" the query that was submitted.)
An example of a simple (non-xml) XQuery query is:
let $title := /book/title
return <returnedTitle> { $title } </returnedTitle>
which is reasonably intuitive, it says "find all elements <title> within element <book> and return these as XML fragments each wrapped in an element <returnedTitle>".
This example illustrates some fundamental differences from CQL:
- With XQuery, you don't get a result set maintained at the server, rather, you get all the results back in the query response. This is because, unlike Z39.50 (and SRU) there isn't a presumption of a protocol. (Actually, it seems, there is a presumption of no protocol.) CQL doesn't address how results are to be returned, rather, it assumes that there is a protocol which governs its use, for example (but not necessarily), SRU.
- With XQuery, you search according to a search schema, for example, there is a presumption in the above example that there are <title> elements with <book> elements. Z39.50 (and SRU) use abstract access points instead, for example when you search on 'title' the server interprets '"title' however it chooses.
- There really is no concept of record in the XQuery data model. In the above example you may get a bunch of titles returned, but they may all be from the same document. You would get a hit count, but it wouldn't be the number of records.
XQuery could be very useful and appropriate for searching, for example, the congressional record, assuming that it is exposed in XML, where the specific schema of the data is well-known. It would also be useful for relational databases. It would not be useful for bibliographic data, record-based databases, or for metasearching across diverse databases; instead, CQL/SRU, will be more appropriate.
OpenURL and SRU
SRU is sometimes compared with OpenURL. People ask "why isn't OpenURL used for searching, rather than SRU?"
OpenURL packages metadata, about a desired resource, along with additional context information, into a URL. SRU packages query parameters, which similarly are often metadata about a desired resource, along with protocol information, into a URL. So there are similarities between OpenURL and SRU.
But the comparison is superficial. It's useful to look more closely at the OpenURL model. OpenURL links a user to an appropriate resource. It does this in part by including bibliographic information about the resource. As that information might lead to several resources, context information is also included in the URL, to help select the most appropriate from among those several resources.
In a typical OpenURL scenario a user (requester) accesses a server (referrer) on which there is an article (referring entity) which cites a reference (referent). The reference looks like it might be a normal link that the user can click, but it's really an OpenURL -- an HTTP URL, not a URL for a specific resource, but instead, metadata about these context entities (requester, referrer, refering entity, referent). And the base url (i.e. where the url is being sent) isn't the location of the desired resource, instead it is what's known as a resolver -- a server designed to take all this information and determine what resource the user really wants (or is "most appropriate").
Note: There may be an additional step: when the user clicks on the link it might first get a menu of services: full text, abstract, table of contents, reviews, etc. The user selects one and this desired service type is also included in the URL.
So SRU and OpenURL serve very different purposes. One selects records based on search criteria, the other selects a single resource, the one deemed "most appropriate", from among a number of potential resources, based on context information.
Note also that OpenURL intends to locate a single resource, while SRU finds all resources that meet specified criteria. OpenURL generally returns full text of the resource (or if not full text of the resource, text for some desired service). With SRU, the request can specify the format of the response records, and the response might not include any record, but instead indicate a result count (and the user may subsequently retrieve records from the result set).
Thus SRU is an information retrieval protocol. OpenURL is not. On the other hand, OpenURL, clearly, addresses functions that SRU doesn't contemplate.
OAI, SRU, and OpenURL: How might these three work together?
These three can work together in a complimentary manner. First consider the complimentary roles of OIA and SRU.
In the OAI model, a service provider accesses a metadata repository via the OAI protocol, to harvest records from the repository. There is little selectivity available to the service provider, it simply takes the metadata records available, subject to some basic filtering, for example time of creation or sub-repository name. The result is a somewhat random collection of metadata records. The OAI protocol does not address how that database might be searched. That's where SRU would come in. The service provider would interface an SRU server to the database of metadata records for an SRU client to access.
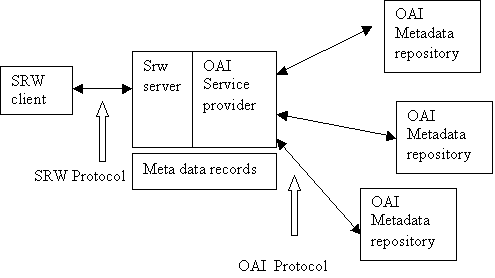
In this model, where an SRU server has access to harvested metadata, an OpenURL provider can effectively utilize an SRU client who has access to this server.
In the OpenURL model as described above a user accesses an article which cites a reference, which looks like a normal link that the user can click, but it's really an OpenURL, filled with metadata. The system that provides the OpenURL needs access to metadata in order to populate the OpenURL with metadata and also to keep the metadata up-to-date. For example, the system might want to create an OpenURL for a resource for which it has an identifier, or a title; it would search the respository on that identifier or title, thereby obtaining other metadata elements for the resource.
SRU: Post Vs. Get
The question "why not POST an SRU request instead of (or as an alternative to) using GET?" was raised, because:
- SRU query URLs sometimes exceed the maximum length supported by
some toolkits or servers.
By using HTTP POST (rather than GET) to transmit the URL the substring following the base URL would be sent in the body of the HTTP message; this effectively avoids string-length limitations, since usually the base URL isn't terribly long.
- Certain queries are difficult or impossible to send via GET because of character encoding complexities. There is no way to indicate character encoding with GET; with POST, you can explicitly state the character-set.
SRW uses POST; currently SRU uses GET, and the suggestion is to also allow SRU via POST. Then we would effectively have three methods for how SRW/U is handled via HTTP:
- POST with SOAP (SRW)
- GET (SRU)
- POST without SOAP (SRUP - new POST option for SRU)
There are two issues:
Resolution
Currently SRW and SRU messages go to the same base URL where (some toolkits assume) that anything received via POST is SRW, so the message is passed to SOAP, while GET messages go to a different process for SRU processing. In other words the software distinguishes SRW from SRU solely based on HTTP method, POST or GET. By adding this third method, they wouldn't be able to get away with that any longer.
One possible solution is to use different addresses for the different methods, and there are a number of suggestions for resolution, for example, Explain can provide a list of methods supported and corresponding addresses, or this could be done via <links> in <databaseInfo>. And it is also suggested that Explain could make this distinction without distinct addresses: You can already say SRW/U meaning that you support SRW and SRU at the same address. With an addition of a 'method' attribute you can say if you support SRU via POST or GET. (The value would be a space separated list. So you could have: <... protocol="SRW/U" method="POST GET">.)
Complexity of Adding a Third Method
The consensus appears to be that the cost of this complexity is worth the gain. Not allowing SRUP would mean that some queries will be impossible without SOAP, and the people affected are likely to just implement it anyway, allowed or not.
So, assuming we define a third method, SRUP, the SRU choices for an implementor (leaving aside SRW considerations for the moment) become:
- SRU alone
- SRU + SRUP
- SRUP alone
However, simple clients are most likely to continue to use SRU GET, so it is important that choice (3) be disallowed. The best way to do that is to explicitly declare that conformance to SRU requires that GET be implemented (whether POST is implemented or not). This argues in favor of formalizing SRUP, because otherwise there would be no context for such a conformance rule.
Opensearch Vs. SRU Parameter Names
One of the interesting features of openSearch is that the parameter names are not fixed. The parameters defined by the openSearch query spec are (1) the query, (2) number of records desired, (3) offset. There are analogous SRU parameters. In SRU these three parameters have well-defined names. However the openSearch spec does not define names for these parameters, rather it allows an openSearch server to use whatever names it wants. For example, consider these three queries:
- http://www.solent.tv/opensearch.aspx?q=chicago%20white%20soxr&c=20&s=1
- http://www.koders.com/?s=chicago%20white%20sox&p=1&output=rss
- http://www.unto.net/aws?searchTerms=chicago%20white%20sox&
searchIndex=SportingGoods&style=desc&format=osrss
In (1) the query is supplied by the parameter with name 'q'. In (2) the query parameter is 's', and in (3), 'searchTerms'. Note also that there are additional parameters beyond the base three, for example 'output' in (2) and 'format' in (3).
This works, because openSearch requires that a server provide a so-called openSearchDescription, which is in a real sense analogous to ZeeRex, which "explains" all the parameters.
The reasoning for this (as explained by the openSearch developer) is to allow a company to use an existing query format, that is, the same parameters, as long as the base three match up semantically.
(And it is interesting to observe, this is working in the real world, based on the idea of self-configuring clients, the same concept as that of ZeeRex.)
Here is a sample xml element, <url>, which is included in a description file and server to explain the openSearch parameters accepted:
<Url>http://search.athenscounty.lib.oh.us/cgi-bin/koha/opensearch?|
q={searchTerms}&searchindex=NPLKoha&startPage={startPage}
& count={count}&relevanceScale={relevanceScale}</Url>
Thus "q={searchTerms}" serves to explain that the parameter name 'q' is to be used for the query, etc. Note also that this example defines a local parameter, 'relevanceScale'. Local parameters are not expected to necessarily be supported by the client.
SRU and Z39.50
The SRU Initiative recognizes the importance of Z39.50 (as currently defined and deployed) for business communication. While SRU focuses on getting information to the user, building on Z39.50 semantics enables the creation of gateways to existing Z39.50 systems.
SRU combines several Z39.50 features, most notably, the Search, Present, Sort and Scan Services. Additional features/services may be added later or defined later as new web services.
Z39.50 Concepts Retained in SRU
- Result Sets
- Abstract Access points
- Abstract Record schemas
- Explain
- Diagnostics
Some SRU Differences from Z39.50
- Result Set Named by Server
In contrast to Z39.50 where the client names the result set, for SRU the server assigns the result set id. - Connections, Sessions, State
There is no explicit concept of connection, session, or state. - No distinction between server and database
SRU does not distinguish between a server and a database; it is hoped that elimination of the database concept will effect significant simplification (since the multiple-database concept in Z39.50 has caused such complexity), for example Explain is significantly simplified (and hopefully it will therefore become more widely implemented). - Single record syntax
All SRU records are retrieved according to a single record syntax (XML) and therefore the (Z39.50) concept of record syntax is not necessary. The (Z39.50) concepts of element set/specification and schema are represented by XML schemas, e.g. Dublin Core, Onix, MODS, and MarcXml. - String Query
SRW specifies string queries base on the query language, CQL. Z39.50, in contrast, does not define a human-readable query language. The CQL syntax includes the result set name, and supports both the capability to qualify a result set (e.g. "records in result set 'A' where title is 'B' ") and to specify only a result set name (e.g. "records in result set 'A'") analogous to a Z39.50 Present. - Flat Indexes
Flat indexes are defined, rather than utilizing attribute vectors as in traditional Z39.50. - Simplified Explain
Explain information is not based on the Z39.50 Explain concept of searching an Explain database for specific information, but rather, all explain information for a server is contained in a single file, retrieved in a single operation. Explain information includes supported access points and record schemas. The Explain simplification also owes in large part to the SRW simplification discarding multiple databases and record syntaxes, and it is hoped that there will be more motivation to implement the SRW version of Explain (than there was to implement the Z39.50-1995 Explain) because of the substantial simplification. - XML instead of ASN.1.
XML is used for abstract syntax as well as encoding. ASN.1/BER is not used.
What are the potential advantages of SRW over SRU?
The benefits of SRW are: better extension support, authentication, web service features.
Federated Search
Eric Morgan
asks: What are some techniques to implement federated search against
a collection of SRU-accessible indexes?
Responses
Ralph LeVan
We created a federating database that forwards a search to
multiple databases, accumulates the responses to build indexes for
a new (single) virtual database, and provides search against this new
database. It assumes similarity among the remote databases - does no
query mapping or record syntax normalization but uses the explain record
from the first database on its list as its own explain record.
Rob Sanderson
Scan all known indexes on remote database and create a document
that represents that server, with a field containing all terms in a given
index. Index these documents. For a given request, search the proxy
documents constructed to find databases that are likely to have a match.
Rank them by relevance using the frequency of the term in the index (as
retreived with scan). Then search the matching databases in order of
relevance. If you're expecting to make this available over the web, then
limiting the number of parallel searches at any one time is a good idea
or you'll blow away either your own server or the remote database.
Matthew Dovey
Let's say we search three databases A, B, C.
We send a searchRetrieve request to all three ( no records to be returned). A says
it has 15 results, B says 10, and C,
5. In our user interface we only display 10 records at a time, so we
start by displaying the first 10 from A (a second
searchRetrieve this time asking for 10 records). If the user selects
the next page, we pull back the remaining 5 from A,
and the first 5 from B, and so on.
An optimization/improvement:
the "Centroid" approach
Retrieve the list of terms from an index from each database via scan.
For example, say:
- Database A for authors returns the list:
- Smith - 15 occurences
- Shakespeare – 10 occurences
- Morgan - 1 occurence
- Dovey - 10 occurences
- Sanderson – 15 occurences
- Database B the list:
- Smith - 28 occurences
- Morgan - 10 occurences
- Dovey -5 occurences
- Database C:
- Smith - 28 occurences
- Sanderson – 10 occurences
Searching for "author=Morgan", there is no point in sending
a request to database C, and probably not much point
sending to A either. This approach reduces the number
of database you need to search for a particular query. (However, it
isn't very good if you are trying to locate particular items, for example
if these were databases of rare
books.)