[Table of Contents | Previous Section]
Section 3.1.6 (Model of a Result Set) notes that in the extended result set model for searching, the target maintains unspecified information associated with each record, which may be used as a surrogate for the search that created the result set. Query specifications may indicate under what condition the extended model applies and the nature of the unspecified information. This appendix provides examples of information that the target might maintain to perform proximity operations requiring the extended model, or to evaluate restriction operands.
ERS.1 Extended Result Set Model
for
Proximity
In the extended result set
model for proximity, the target maintains information associated with each record
represented by the result set, that may be used in a proximity operation as
a surrogate for the search that created the result set.
Example 1:
Let R1 and R2 be result sets produced by Type-1 query searches
on the terms 'cat' and 'hat'. In the extended result set model for proximity,
the target maintains sufficient information associated with each entry in R1
and with each entry in R2 so that the proximity operation "R1 near R2" would
be a result set equivalent to the result set produced by the proximity operation
"cat near hat" ("near" is used informally to refer to a proximity test).
The manner in which the target maintains this information is not prescribed by the standard. The concept of "abstract position vectors" may used to describe the effect of the proximity test. A target system may implement the proximity test in any way that produces the desired results.
An abstract position vector might include a proximity unit and a sequence of position identifiers.
Example 2:
Let R1 and R2 be result sets produced by searches on the terms 'cat' and 'hat'.
Record 1000 contains 'cat' in paragraphs 10 and 100 and 'hat' in paragraphs
13 and 200. So record 1000 is represented in both R1 and R2. In R1, it might
include the two position vectors (paragraph, 10) and (paragraph, 100). In R2,
it might include the two position vectors (paragraph, 13) and (paragraph, 200).
R3 = "R1 within 10 paragraphs of R2" would identify this record, and a position
vector might be created (paragraph, 10, 13).
Subsequently, suppose R4 represents "rat before bat" and includes record 1000 with position vectors (paragraph, 5, 8) and (paragraph, 15, 18). Then:
Note: In these two examples, the position vectors might instead be (paragraph, 10, 13, 15, 18) instead of (paragraph, 10, 18); and (paragraph, 5, 8, 10, 13) instead of (paragraph, 5, 13). Different implementations might interpret extended proximity tests differently.
Neither the information that the target maintains (associated with result set entries to be used in the proximity operations) nor the manner in which the target maintains this information, is prescribed by the standard. The above is supplied as an example only.
ERS.2 Extended Result Set Model for Restriction
The
Restriction operand specifies a result-set-id and a set of attributes. It might
represent a set of database records identified by the specified result set,
restricted by the specified attributes, as in example 1 (below). It might represent
a set of records from the database specified in the Search APDU, indirectly
identified by the specified result set and restricted by the specified attributes,
as in example 2.
Example 1:
Let R be the result set produced by a search on the term
'cat'.
Result set position:
Then "R restricted to 'author'" might produce the result set consisting of the entries 2 and 3 of R.
In the extended result set model for restriction, the target maintains information that allows this type of search to be performed. In this example, the target might maintain the following information with the entries in result set R:
Result set position:
Example 2:
In this example, R and C are two databases. R is a "registry"
database containing records about chemical substances, each of which is identified
by a unique registry number. C is a bibliographic database, containing bibliographic
records for documents about chemical substances. The registry number is a searchable
field in both databases. A registry number identifying a record in R may occur
in one or more logical indexes for database C.
For example, the "preparations" index for database C contains registry numbers of substances that are cited in its documents as being used in preparations.
In this example, a search is performed against database R, creating result set L, which will in effect contain registry numbers representing records in database R, each of which uniquely identifies a chemical substance. A second search is performed against database C with the operand "L restricted to 'preparations'." This restriction is expressed by applying the "preparations" attribute to result set L. The search is performed by looking for registry numbers from result set L that occur in the "preparations" index for database C. The result set represents the records in C where a registry number contained in result set L occurs as a preparation.
In the extended result set model for restriction, the target maintains information that allows this type of search to be performed. In this example, the target might maintain, with each entry in L, a list of identifiers of records in C for which the registry number occurs as a preparation.
Neither the information that the target maintains (associated with result set entries to be used in the evaluation of a Restriction operand), nor the manner in which the target maintains this information, is prescribed by the standard. The above are supplied as an example only.
Search and retrieval are the two primary functions of Z39.50. Searching is the selection of database records, based on origin-specified criteria, and the creation by the target of a result-set representing the selected records. Retrieval, idiomatically speaking, is the transfer of result set records from the target to the origin.
This appendix describes retrieval, and thus assumes the existence of a result set. For simplicity, it is assumed that the result set has a single record (although Z39.50 retrieval allows an origin to request the retrieval of various combinations of result set records) and this appendix focuses on the capabilities provided by Z39.50 retrieval for retrieving information from that record.
RET.1 Overview of Z39.50
Retrieval
Though
retrieval is considered informally to be the transfer of result set records,
a result set, logically, does not contain records. Rather, it contains
logical items (sometimes referred to as "answers"); each item includes
a pointer to a database record (the term "result set record" is an
idiomatic expression used to mean "the database record represented by a result
set item").
Moreover, a database record, as viewed by Z39.50, is purely a local data structure. In general Z39.50 retrieval does not transfer database records (that is, the target does not transfer the information according to its physical representation within the database), nor does Z39.50 necessarily transfer all of the information represented by a particular database record; it might transfer a subset of that information.
Thus the "transfer of a result set record" more accurately means: the transfer of some subset of the information in a database record (represented by that result set entry) according to some specified format. This exportable structure transferred is called a retrieval record. (Multiple retrieval requests for a given record may result in significantly different retrieval records, both in content and structure.)
Z39.50 retrieval supports the following basic capabilities:
Correspondingly, Z39.50 retrieval has four primary functions:
Note: element selection pertains to retrieval, and should not be confused with record selection which pertains to searching. Element selection pertains to selection of information elements from already-selected database records.
RET.2 Retrieval Object
Classes
This
section, RET.2, describes object classes used by these retrieval functions:
RET.3 describes in detail specific object definitions that are defined within
this standard.
Following is a brief overview of the object classes.
An elementSpec occurs within a Z39.50 Present request, and is used primarily for selection. In its most basic form, an elementSpec is a request for specific elements (a set of elementRequests).
A tagSet defines a set of elements, and specifies names and recommended datatypes for individual elements within that set. The name of an element is called its tag, and may be used alone (in an elementRequest) or accompanying the element it names (within a retrieval record).
A schema defines an abstract record structure (see RET.2.2). The schema definition refers to one or more tagSets.
Although an elementSpec is used primarily for selection, it might have representation aspects: each elementRequest may include a variantRequest, used primarily for element representation, to specify the particular form of an element, for example how an element is to be formatted. (However, a variantRequest may include limited selection: it might ask for a specific piece or fragment of an element.)
A variantRequest is one of three usages of a variantSpec:
A record syntax is applied by the target to the set of elements selected by an elementSpec (and possibly transformed by appliedVariants) resulting in a retrieval record.
Summarizing:
RET.2.1 Element Specification Features and
TagSets
An
elementSpec may be included in a Present request to specify the desired elements
to comprise a retrieval record. For example, the origin might request that the
retrieval record consist of the two elements 'author' and 'title'. The elementSpec
may express this in one of two ways:
The use of an element set name as an elementSpec has a significant limitation: one would need to be defined for every possible combination of elements that might be requested.
For Z39.50 version 2, only the primitive form is allowed; the elementSpec must be an element set name (whose ASN.1 type is VisibleString). Version 3 allows the elementSpec to alternatively assume the ASN.1 type EXTERNAL (thus referencing an external definition, which is presumably, though not necessarily, described in ASN.1). The following illustrate some of the features that may be provided by an elementSpec, by progressively complex ASN.1 examples.
RET.2.1.1. Simple numeric
tags
A simple
elementSpec might specify a list of elements. The elementSpec definition could
be:
In this example, each element requested is represented by an integer. Both origin and target are assumed to share a common definition, a tagSet, which assigns integers to elements. The integer is the name, or tag, of the element. In this example, the tagSet might assign the integers 1 to 'title' and 2 to 'author'.
RET.2.1.2 String tags
It is not always
desirable to restrict element tags to integers. String tags are useful
for some applications. So the element request might take the slightly more complex
form:
ElementRequest ::= StringOrNumeric
Note that StringOrNumeric is a type defined within, and exported by Z39-50-APDU, defined as:
StringOrNumeric ::= CHOICE{
numeric [1] IMPLICIT INTEGER,
string [2] IMPLICIT InternationalString}
In this case, the tagSet might declare that "author may also referenced by the string tag 'author', and title by 'title'."
RET.2.1.3 Tag Types
Often it will be
necessary (or useful) to request elements not all of whose tags are defined
by a single tagSet. This capability presents an important benefit, allowing
multiple name spaces for tags, so that tagSet definitions may be developed independently.
However, it requires that tags be qualified by reference to tagSet.
A schema definition (see RET.2.2) may assign an integer to identify a tagSet (it identifies the tagSet only within the context of the schema definition). This tagSet identifier is called a tagType. Note that a tagSet definition is a registered object and thus is persistently identified by an object identifier. The (integer) tagType is used as a short-hand identifier.
Extending the above example to incorporate tagTypes, the elementRequest could be defined as:
ElementRequest ::= SEQUENCE{
tagType [1] IMPLICIT INTEGER,
tagValue [2] StringOrNumeric}
RET.2.1.4 Tag Occurrence
A database
record often contains recurring elements. An origin might want the Nth occurrence
of a particular type of element (e.g. "the fourth image"). To introduce recurrence
into the above example, the elementRequest could be defined as:
ElementRequest ::= SEQUENCE{
tagType [1] IMPLICIT
INTEGER OPTIONAL,
tagValue [2] StringOrNumeric,
tagOccurrence [3] IMPLICIT INTEGER}
RET.2.1.5 Tag Paths
A database record
is not necessarily a flat set of elements, it may be a hierarchical structure,
or tree (where leaf-nodes contain information). An origin might request, for
example "the fourth paragraph of section 3 of chapter 2 of book 1" ('book',
'chapter', 'section', and 'paragraph' might be tags). This example introduces
the concept of a tag path, which is simply a nested sequence of tags (each tag
within the sequence is qualified by a type and occurrence). A tag path can be
incorporated by replacing the first line of ASN.1 in the previous example, with:
ElementRequest ::= TagPath
TagPath ::= SEQUENCE OF SEQUENCE{
RET.2.1.6 VariantRequests
Finally, the
origin may wish to qualify an elementRequest with a variantRequest, to specify
a particular composition (e.g. PostScript), language, character set, formatting
(e.g. line length), or fragment.
ESpec ::= SEQUENCE OF ElementRequest
ElementRequest ::= SEQUENCE{
TagPath,
VariantRequest OPTIONAL}
Where TagPath is defined as in the previous example. Variants are described in RET.2.3.
RET.2.2 Schema and Abstract Record Structure
A
database schema represents a common understanding shared by the origin and target
of the information contained in the records of the database represented by schema.
The primary component of a schema is an abstract record structure, ARS.
It lists schema elements in terms of their tagPaths, and supplies information
associated with each element, including whether it is mandatory, whether it
is repeatable, and a definition of the element. (It also describes the hierarchy
of elements within the record; see RET.2.2.5.)
An ARS is defined in terms of one or more tagSets. The schema itself may define a tagSet, and may also refer to externally defined tagSets. In the simple example of an ARS that follows, assume that the following tagSet has been defined:
| Tag | Element | Recommended dataType |
| 1 | title | InternationalString |
| 7 | name | InternationalString |
| 16 | date | GeneralizedTime |
| 18 | score | INTEGER |
| 14 | recordId | InternationalString |
<locally
defined string
tag> objectElement InternationalString or
OCTET STRING
In the following example ARS, each "schema element" refers to an element from the above tagSet.
In this example, for objectElement, the schema would indicate that the target is to assign some descriptive string tag. For example, if the element is a fingerprint file, the tag might be 'fingerPrintFile'. (In that case, the content of element 'name', tag 7, might identify the person who is the subject of the finger prints.) Since it is the only element in the ARS with a string tag, the origin will recognize it as the objectElement.
| Schema Element |
Mandatory? | Repeatable? | Definition |
| title | yes | no | A set of words that conveys the main idea of the record. |
| name | no | yes | One or more individuals associated with the object element; it could, foe example, be an author or an organization. |
| date | no | no | A date associated with the record. |
| score | no | no | Represents the numerical score of the record based on its relevance to the query. |
| recordId | no | no | An identifier of the record unique within the target system. |
| objectElement | yes | no | Contains object information for the record. It may be text, image, etc. |
RET.2.2.1 Relationship of Schema and
TagSet
In
the above example, at first glance it appears there need not be separate tables
for tagSet and ARS, they could be combined into a single table. When the tagSet
is defined within a schema, then there may be no need to distinguish between
the tagSet and schema. However, the tagSet might instead be defined externally
and referenced by the schema.
A schema may define a tagSet as in the example above, and it need not be registered. The schema could simply assign an integer tagType to identify the tagSet. The tagSet could then be used only by that schema. But some of the elements in the above example might also be included in a different schema. For example, another schema might also define title and name, and that schema should be able to use the same tags. For this purpose, tagSets may be registered, independent of schema definitions.
It is anticipated that there will be several, but not a large number of tagsets defined, and that many schemas will be able to define an ARS referencing one or more registered tag sets, without the need to define a new tagSet. (There will be more than one tagSet defined because it would be difficult to manage a single tagSet that meets the needs of all schemas.)
RET.2.2.2 TagTypes
As noted in RET.2.1.3,
within a Present request or Present response elements are identified by their
tag, and tags are qualified by tag type. The tag type is an integer,
identifying the tagSet to which it belongs. A schema lists each tagSet referenced
in its ARS and designates an integer to be used as the tag type for that tagSet.
Z39.50 currently defines two tagSets, tagSet-M and tagSet-G. These are described in RET.3.4. TagSet M includes elements to be used primarily to convey meta-information about a record, for example dateOfCreation; tagSet-G includes primarily generic elements, for example 'title', 'author'.
Among the schema elements defined in the example above, title and name are defined in tagSet-G; date, score, and recordId are defined in tagSet-M.
The schema might provide the following mapping of tagType to tagSet:
1 --> tagSet-M
2 --> tagSet-G
3 --> locally defined tags (intended primarily for string tags, but numeric tags are not precluded).
In the notation below, where (x,y) is used, 'x' is the tagType and 'y' is the tag. In the ARS above the following column would be inserted on the left:
TagPath
(2,1)
(2,7)
(1,16)
(1,18)
(1,14)
(3,<locally defined string tag>)
RET.2.2.3 Recurring
objectElement
The
schema becomes only slightly more complex if multiple object elements (i.e.
multiple occurrences of the element objectElement) are allowed. The schema could
indicate that each occurrence of objectElement is to have a different string
tag. The entry in the 'repeatable' column in the ARS, for objectElement, would
be changed from 'no' to 'yes'.
For example, suppose a record includes a fingerprint file, photo, and resume, all describing an individual (and the element 'name' might identify the individual that they describe). The string tags for these three elements respectively might be 'fingerPrint', 'photo', and 'resume'. The origin would recognize each of these elements as an occurrence of objectElement, because the schema designates that only objectElement may have a string tag. (This is not to imply that the origin would recognize the type of information, e.g. fingerprint, from its string tag; but the origin might display the string tag to the user, to whom it might be meaningful.)
The ARS would be as follows (definition column omitted):
Tag path Element Mandatory? Repeatable?
(2,1) title yes No
(2,7) Name no Yes
(1,16) Date no No
(1,18) Score no No
(1,14) RecordId no No
(3, Object
<stringTag>) Element yes Yes
RET.2.2.5 Structured Elements
In the following example, hierarchy is introduced; the ARS includes structured elements (i.e. elements whose tagPath has length greater than 1). In the examples above the ARSs are flat; all elements are data- elements, i.e. leaf-nodes. The ARS below is part of a schema for a database in which each record describes an information resource. It assumes the following tagSet:
| Tag | Element Name | Recommended DataType |
| 25 | linkage | InternationalString |
| 27 | recordSource | InternationalString |
| 51 | purpose | InternationalString |
| 52 | originator | InternationalString |
| 55 | orderProcess | InternationalString |
| 70 | availability | (structured) |
| 90 | distributor | (structured) |
| 94 | pointOfContact | (structured) |
| 97 | crossReference | (structured) |
The notation (x,y)/(z,w) is used below to mean element (z,w) is a sub-element of element (x,y). In the "Schema Element Name" column, indentation is used to indicate subordination. For example, distributorName, a data element, is a sub-element of the structured element distributor, which in turn is a sub-element of the structured element availability. In this example, the schema designates that the
tagType for the above defined tagSet is 4.
Several elements in the ARS below are (implicitly) imported from tagSet-G (those with tagType-2). These are: title, abstract, name, organization, postalAddress, and phoneNumber.
| SchemaElement Tag Path |
Schema Element Name |
| (2,1) | title |
| (2,6) | abstract |
| (4,51) | purpose |
| (4,52) | originator |
| (4,70) | availability |
| (4,70)/(4,90) | distributor |
| (4,70)/(4,90)/(2,7) | distributorName |
| (4,70)/(4,90)/(2,11) | distributorOrganization |
| (4,70)/(4,90)/(2,14) | distributorTelephone |
| (4,70)/(4,55) | orderProcess |
| (4,70)/(4,25) | linkage |
| (4,94) | pointOfContact |
| (4,94)/(2/7) | contactName |
| (4,94)/(2,10) | contactOrganization |
| (4,94)/(2,11) | contactAddress |
| (4,97) | crossReference |
| (4,97)/(2,1) | CrossReferenceTitle |
| (4,97)/(4,25) | CrossReferenceLinkage |
| (4,97) | recordSource |
The ARS describes an abstract database record consisting of title, abstract, purpose, originator, availability, point of contact, crossReference, and recordSource. These are the "top-level" elements, among which, Availability, pointOfContact, and CrossReference are structured elements, and the others are data elements. Availability consists of distributor, orderProcess, and Linkage; among these, distributor is a structured element.
RET.2.3 Variants
An element might be
available for retrieval in various forms, or variants. The concept
of an element variant applies in three cases:
Correspondingly, and more formally, a variant specification (variantSpec) takes the form of a variantRequest, appliedVariant, or supportedVariant. In all cases, a variantSpec is a sequence of variantComponents, each of which is a triple (class, type, value). 'class' is an integer. 'type' is also an integer and a set of types are defined for each class. Values are defined for each type.
A variantSet definition is a registered object (whose object identifier is called a variantSetId) which defines a set of classes, types, and values that may be used in a variantComponent. A variantSpec is always qualified by its variantSetId, to provide context for the values that occur within the variantComponents (in the same manner that an RPN Query includes an attribute set id, to provide context for the attribute values within the attribute lists).
The variant set definition variant-1 is defined in Appendix VAR, and is described in detail, in RET.3.3.
RET.2.4 Record Syntax
The target applies
a record syntax to an abstract database record, forming a retrieval record.
Record syntaxes fall into two categories: content-specific and generic. Content-specific
record syntaxes include:
Generic record syntaxes are further categorized: they are structured or unstructured. Structured record syntaxes are able to identify TagSet elements. GRS-1, a generic, structured syntax, is defined in REC.5, and is described in detail in RET.3.2. SUTRS (Simple Unstructured Text Record Syntax) is a generic, unstructured syntax, defined in REC.2.
RET.3 Retrieval Objects Defined in this
Standard
In
the remainder of this Appendix, detailed descriptions are provided below for
the following retrieval objects defined in this standard: element specification
format eSpec-1, record syntax GRS-1, variant set variant-1, and tagSets tagSet-M
and tagSet-G. Within these descriptions it is assumed that these objects are
used together; for example, in the description of eSpec-1 it is assumed that
GRS-1 is to be used as the record syntax. In general, however, no such restriction
applies; eSpec-1 may be used as an element specification in conjunction with
SUTRS for example.
RET.3.1 Element Specification Format
eSpec-1
The
element specification format eSpec-1 is defined in Appendix ESP. An element
specification taking this form is basically a set of elementRequests, as seen
in the last member of the main structure:
elements [4] IMPLICIT SEQUENCE OF ElementRequest ......
Each elementRequest may be a "simple element" or a "composite element," as distinguished by the ElementRequest definition:
ElementRequest::= CHOICE{
simpleElement [1] ...
compositeElement [2] ...
Simple elements are described in RET.3.1.1. A composite element is constructed from one or more simple elements, described in RET.3.1.2. Note however an elementRequest which takes the form of simpleElement might actually result in a request for multiple elements. See RET.3.1.1.3.
The element specification may include additional elementRequests, resulting from 'elementSetNames' in the first member of the main sequence. All elementRequests resulting from 'elementSetNames' are simple elements.
Also included in the main structure are a default variantSetId and a default variantRequest. These are described in RET.3.1.1.5.
RET.3.1.1 Simple Element
A request for
a simple element consists of the tagPath for the element, together (optionally)
with a variantRequest. The tagPath identifies a node of the logical tree (or
possibly several trees) representing the hierarchical structure of the abstract
database record to which the element specification is applied.
A tagPath is a sequence of nodes from the root of a tree to the node that the tagPath represents, where each node is represented by a tag. The end-node of a tagPath might be a leaf-node containing data, or a non-leaf node; in the latter case, the request pertains to the entire subtree whose root is that node, and GRS-1 will present the subtree recursively (see RET.3.2.1.1).
RET.3.1.1.1 Tag
Each tag is qualified
by a tagType. Thus a tag consists of a tagType and a tagValue. (A tag is further
qualified by its "occurrence"; see RET.3.1.1.2.) Each tagType is an integer,
and each tagValue may be either an integer or string.
Every tag along a tagPath is assumed to have a tagType, either explicit or implicit; it may be supplied explicitly within the specification, and if it is omitted, a default applies (the default should be listed within the schema in use). Tags along a tagPath may have different tagTypes.
RET.3.1.1.2 Occurrence
Each node along
a tagPath is distinguished not only by its tag, but also by its occurrence among
siblings with the same tag. A record might contain recurring elements, and the
origin might wish to request the Nth occurrence of a particular element (e.g.
"the fourth image"). The specification of the "occurrence" of a node may be
omitted, in which case it defaults to 1. Occurrence may explicitly be specified
as "last" (this capability is provided for the case where the origin does not
know how many occurrences there are, but however many, it wants the last).
RET.3.1.1.3 Multiple Simple
Elements
In
some cases a 'simpleElement' request (within the ElementRequest structure) results
in multiple sim-
ple elements. This may occur in the following cases:- If a tagPath identifies a non-leaf node, the request represents the entire subtree (it is logically equivalent to individual simple requests for each subordinate leaf-node).
'occurrence' may be specified as 'all, meaning "all nodes with a given tag."
'occurrence' may be specified in the form of a range (e.g. 1 through 10).
The tagPath may include a wild card (see RET.3.1.5) in lieu of a specific tag.
RET.3.1.1.4 Wild-cards
A tagPath may
be viewed as an expression containing tags and wild cards. There are two types
of wild cards, wildThing and wildPath, described in RET.3.1.1.4.1 and RET.3.1.1.4.2.
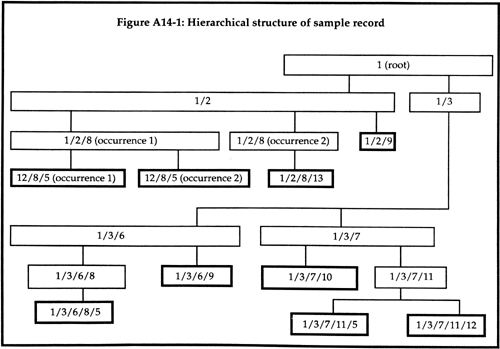
For this discussion of wild-cards, consider the sample record whose hierarchical structure is shown in the diagram below.
Each cell in the diagram represents an element whose tagPath is indicated within the cell. The numbers within the tagPath are tagValues; for simplicity, tagTypes are omitted, and assumed all to be the same. Leaf-nodes are highlighted by double-lined cells.
For example, the tagPath 1/3/7 represents the (non-leaf-node) element with tag 7 subordinate to the element with tag 3 subordinate to the element with tag 1. 1/3/7/11/12 represents the element whose (leaf-) node has tag 12.
RET.3.1.1.4.1 WildThing
A tagPath expression
may include the wild card 'wildThing' in lieu of a tag. WildThing takes the
form of an occurrence specification. For example, the tagPath expression '1/2/wildThing
(occurrence 3)' would represent the node 1/2/9, because it is the third child
of the node 1/2.
The expression '1/wildThing (occurrence 2)' would be equivalent to the path 1/3 (it refers to the entire subtree whose node has tag 3).
RET.3.1.1.4.2 WildPath
A tagPath expression
may include the wild card 'wildPath' in lieu of a tag. WildPath matches any
sequence of tags, along any path such that the tag following wildPath in the
expression follows that sequence in the matched path. For example, either of
the expressions 'wildpath/5' or '1/wildPath/5' would result in all paths ending
in 5. It would match:
1/2/8 (occurrence 1)/5 (occurrence 1)
1/2/8 (occurrence 1)/5 (occurrence 2)
1/3/6/8/5, and
1/3/7/11/5
The expression '1/2/wildPath/5' would match the first two listed above, and the expression '1/3/wildPath/5' would match the last two.
RET.3.1.1.5 Variant Request
Each request
for a simple element may optionally include a variantRequest. Note that the
main structure of eSpec-1 optionally includes 'defaultVariantRequest'. If the
element request does not include a variantRequest then 'defaultVariantRequest'
applies if it occurs in the main structure. If the element request does not
include a variantRequest and 'defaultVariantRequest' does not occur in the main
structure, there is no variant request associated with the element request.
The main structure also optionally includes 'defaultVariantSetId'. A variant specification may or may not include a variantSetId. If the element request includes a variantRequest which does not include a variantSetId, then 'defaultVariantSet' applies. (If the element request includes a variantRequest which does not include a variantSetId, and if 'defaultVariantSet' does not occur in the main structure then the variantRequest is in error.)
RET.3.1.2 Composite
Elements
An elementRequest
for a compositeElement takes the form of a list of simple elements (as described
in RET.3.1; alternatively, the simple elements may be specified by one or more
element set names), a delivery tag, and an optional variantRequest. The simple
elements are to be combined by the target to form a single (logical) element,
to which the (optional) composite variant is to be applied, and the target is
to present the element using the supplied delivery tag.
RET.3.2 Generic Record Syntax
GRS-1
A
GRS-1 structure is a retrieval record representing a database record. Its logical
content is a tree representing the hierarchical structure of the abstract database
record, or a sequence of trees if the abstract record itself does not have a
root.
RET.3.2.1 General Tree
Structure
The
top level "SEQUENCE OF TaggedElement" might be a single instance of TaggedElement,
representing the root of a single tree representing the record (in the degenerate
case, the record consists of a single element). Alternatively, the top-level
SEQUENCE OF might contain multiple instances of TaggedElement, in which case
there is no single root for the record; the record is represented by multiple
trees, any or each of which might be a single element (thus the GRS-1 structure
may represent a flat sequence of elements).
Any leaf-node within the GRS-1 structure might correspond to an individual elementRequest that was included in the corresponding eSpec-1 element specification. A non-leaf node may correspond to an elementRequest; if an eSpec-1 elementRequest tagPath ends at a non-leaf node, then the request is for the entire subtree represented by that node.
RET.3.2.1.1 Recursion and
SubTrees
Each
instance of TaggedElement may, via recursion, contain a subtree. Beginning at
the root of the tree (or at one of the top level nodes) TaggedElement identifies
an immediately subordinate node, via tag and occurrence. If the CHOICE for 'content'
is 'subtree', then the identified node is a non-leaf node: 'subtree' is itself
defined as SEQUENCE OF TaggedElement, so the next level of nodes is thus defined.
Recursion may be thus used to describe arbitrarily complex trees.
RET.3.2.1.2 Leaf-nodes
Along any path
described by the GRS-1 record, eventually a leaf-node is encountered ('content'
other than 'subtree'). The content of the leaf-node is one of the following:
RET.3.2.2 Data
When a leaf-node contains
data, then 'content' is one of the following ASN.1 types: OCTET STRING, INTEGER,
GeneralizedTime, EXTERNAL, InternationalString, BOOLEAN, OBJECT IDENTIFIER,
or IntUnit. That is, the CHOICE for ElementData is one of these, and the actual
data must assume the chosen type. An appliedVariant may also be indicated, by
including appliedVariant from the main structure.
RET.3.2.3 Meta-data
When a leaf-node
contains data or is empty, 'metaData' may be included, containing meta-data
for the element. The meta-data may be included along with the data, or in lieu
of the data if the elementRequest asked that no data be returned (i.e. 'content'
is 'noDataRequested'). Meta-data would not be included when 'content' is 'elementNotThere',
'elementEmpty', or 'diagnostic'.
MetaData for a leaf-node may be any or all of the following:
RET.3.2.3.1 Hits
Associated with an
element may be one or more hit vectors. Each points to a fragment within
the element. Each such fragment bears some relationship to the search which
caused the record (to which the element belongs) to be included in the result
set (from which the record is being presented). Note that the association of
a hit vector to an element is meaningful only within the context of that search.
A hit vector may optionally include a 'satisfier': for example, a term from the query, which occurs within that fragment of the element (to which the hit vector points).
The target might return hit vectors along with an element, so that the origin may be able to quickly locate the satisfying portions of the element, and perhaps even highlight the satisfier(s) for display to the user.
The target might return part of an element and include hit vectors, some of which point within the retrieved portion, and others which point to fragments not included, to indicate to the origin what fragment to request to retrieve other relevant parts of the element.
A hit vector may include location information: offset (location within the element where the fragment begins) and length. Both are expressed in terms of IntUnit, so for example, the location information might indicate an offset of "page 10" and length of "one page," meaning that the satisfier occurs on page 10 (or that the fragment is page 10).
Note: if there are multiple hit vectors with the same satisfier, occurring on the same page, and if the target wishes to indicate 'rank' (see below), it will need to use a unit with finer-granularity than 'page'.
The hit vector may also include 'rank', relative to the other hits occurring within this set of hitVectors. Rank is a positive integer with a value less than or equal to the number of hit vectors. More than one hit may share the same rank.
Finally, the target may assign a token to the hit vector, which points to the fragment associated with the hit. The origin may use the token, subsequently but within the same Z-association, within a variantRequest (in an elementRequest) to retrieve (or to refer to) the fragment.
The target might provide location information, or a token, which may be used subsequently to retrieve the specific fragment. The target might provide both location information and a token: for example, the location information might indicate "page 10"; the origin may subsequently retrieve the pages before and after, inclusive (i.e pages 9-11). If the target also supplies a token, the origin might retrieve the "previous fragment" or "following fragment."
Location information is always variant-specific. A token, however, may be variant-specific or variant-independent. The origin might request "hits: non-variant-specific" for an element (via variant-1), and specify 'noData'. The hit vectors returned would be variant-independent (thus only a token, and no location information, would be included in each hit vector). The origin could subsequently use a token in an elementRequest to retrieve the corresponding fragment, independent of what variantRequest was included in the elementRequest.
The origin might request 'hits: variant-specific' for an element, for a particular variant. The target might return location information or tokens, or both, but in any case, the hit vectors would apply only for that variant. The origin could subsequently use either the location information or token in an elementRequest to retrieve the corresponding fragment, but only when specifying that variant.
As an alternative to hit vectors, see "Highlighting," RET.3.3.1.8.
RET.3.2.3.2 Series Order
The target
might include the meta-data 'seriesOrder' (for a non-leaf node only). It indicates
how immediately-subordinate elements with the same tag are ordered. Values are
listed in TAG.2.1, but may be overridden by the schema.
The values are the same as those for elementOrdering (see RET.3.4.1.2.3) which applies at the record level (i.e. it applies throughout the record, and pertains wherever sibling elements with the same tag occur).
RET.3.3 Variant Set Variant-1
This section
describes the variant set variant-1.
RET.3.3.1 variant-1 Classes
This section
describes the classes, types, and values defined for the variant set variant-1.
RET.3.3.1.1 VariantId
Variant-1 class
1, 'variantId', may be used to supply an identifier for a variant specification.
(There is only one type within class 1, so the variantId is always class 1,
type 1). It is a transient identifier; it may be used to identify a
particular variant specification during a single Z-association. (A variantId
should not be confused with variant set id, which identifies a variant
set definition.)
A variantId may be included within a supportedVariant, variantRequest, or appliedVariant. The variantList for an element may be supplied by the target (see 3.3.2). It consists of a list of supportedVariants for the element. Each may include a variantId, which may be used subsequently by the origin within a variantRequest (within an elementRequest), to identify that supportedVariant (i.e. that variant form of the element), in lieu of explicitly constructing a variant. A variantId may be used within an appliedVariant, supplied by the target in case the origin wishes to use it in a subsequent request, possibly overriding some of the variant parameters.
RET.3.3.1.2 BodyPartType
Variant-1 class
2, 'BodyPartType', allows representation of the structure, or "body part type,"
of an element. It may be used within a supportedVariant, variantRequest, or
appliedVariant.
There are three types: type 1 is ianaType/subType, for content types registered with IANA (Internet Assigned Numbers Authority). Type 2 is for body part types registered by the Z39.50 Maintenance Agency (type 2 is used generally for formats that have not yet been otherwise officially registered). Type 3 is for bilaterally agreed upon body part types.
Following are some of the IANA contentType/Subtypes registered
| Type | Subtype |
| text |
plain |
| application |
octet-stream postscript oda |
| dx |
wordperfect5.1 zip macwriteii msword |
| image |
jpeg gif ief tiff |
| audio | basic |
| video | mpeg |
PostScript, for example, would be indicated by the triple (2,1, 'application/postscript'). SGML is not registered yet by IANA, so it is registered as a Z39.50 body part type. It may be indicated by (2,2, 'sgml/<dtd>') where <dtd> is the name of the SGML dtd.
A Z39.50 body part type will be registered only if it is not registered as an IANA type. If it is subsequently adopted by IANA, it is recommended that it be referenced as such.
RET.3.3.1.3
Formatting/Presentation
Variant-1
class 3, 'formatting', may be included within a variantRequest, appliedVariant,
or supportedVariant. It indicates additional formatting parameters such as line
length, lines per page, font style, and margins.
RET.3.3.1.4
Language/CharacterSet
Variant-1
class 4, 'language/characterSet', may be included within a variantRequest, appliedVariant,
or supportedVariant. It indicates language and/or character set.
RET.3.3.1.5 Piece
Variant-1 class 5,
'piece' may be included within a variantRequest (type 1) or appliedVariant (type
2), to refer to a specific piece or fragment of an element.
The origin may use type 1 to request:
The target may use types 3, 4 (or 5), and 6 in lieu of type 2, to indicate the 'start' and 'end' (e.g. starts at page 1 and ends at page 100) or 'start' and 'howMuch' ( e.g. starts at page 1, 100 pages) of the fragment and optionally, a 'step' size. For example, the target could indicate that the fragment starts at byte 10,000 and ends at byte 20,000 (in this case a step of 1 would be indicated, or implied if 'step' is omitted); or it starts on page 100, ends on page 200, and includes every 5th page.
Similar, the origin may use types 3, 4 (or 5), and 6 to request a fragment. In a variantRequest these types may be used to further qualify a fragment indicated by types 2 and 7. For example, the request might specify a targetToken, previous fragment (5,1,3), as well as a start and end, in which case the start and end are relative to the indicated fragment, i.e., relative to the fragment immediately prior to that indicated by the target token.
The target may use type 7 in an appliedVariant to supply a token as an identifier of the supplied fragment, and the origin may subsequently use the token in a variantRequest to identify that fragment.
RET.3.3.1.6 MetaData Requested
Variant-1
class 6, 'meta-data requested' may be included within a variantRequest, to request
meta-data associated with an element.
The origin might want to know, for example, the cost to retrieve a particular element in PostScript, as well as the page count (of the PostScript form of the element). The following variant specifiers would be included within the variantRequest for that element:
(2,1, 'application/postscript') -- PostScript
(6,1, NULL) -- cost, please
(6,2, Unit:pages) -- size in pages, please
(9,1, NULL) -- no data (just the
-- above metaData)
Alternatively, a variantId might be used in place of a set of explicit specifiers (i.e. in place of the postScript specifier, in this example) if the origin knows the variantId of a variant for which it wants cost or size information. (Although if the origin knows the variantId, it may already have cost or size information because it may have obtained that id within a variantList, and if so, the target may have included the cost and page information within the supportedVariant.)
The origin might also ask for the location of hits within the element (see RET.3.2.3.1). An element might have hits which are specific to a variant, and may also have non-variant-specific hits. The request above might also ask for hits specific to the particular variant (i.e. postScript), using (6,3, NULL) or non-variant-specific hits, using (6,4, NULL). In either case, the request is for the target to return hit vectors within the retrieved GRS record.
The origin may request that the target supply the variant list for an element via the specifier (6,5, NULL). The target would supply the variant list (consisting of a list of supportedVariants) within the GRS structure (not within the appliedVariant). See RET.3.3.2.
The origin may use (6,6, NULL) to inquire whether a particular variant is supported. An example is provided in RET.3.3.2.
RET.3.3.1.7 Meta-data
Returned
Variant-1
class 7, 'meta-data returned' may be included within an appliedVariant or supportedVariant.
There are several categories of element MetaData. Those of class 7: cost, size,
integrity, and separability, are singled out for representation within variant-1,
because the target may include those within a supportedVariant. Other metaData,
including hits and variantList, are included within the GRS-1 structure. Hits
are described in RET.3.2.3.1.
RET.3.3.1.8 Highlighting
Variant-1
class 8, 'highlighting', may be included within a variantRequest or an appliedVariant.
Highlighting may be used as an alternative, or in addition, to hit vectors,
described in RET.3.2.3.1.
The origin may include 'prefix' and 'postfix' in a variantRequest to request that the target insert the specified strings into the actual data, surrounding hits, so that the origin, upon retrieving the data, may simply locate the strings, for fast access to the hits. The origin may use 'server default' in lieu of 'prefix' and 'postfix' to indicate that it the target should select the strings for highlighting.
The target may include 'prefix' and 'postfix' in an appliedVariant to indicate the strings used within the element for highlighting hits.
RET.3.3.2 VariantList
The thoroughness
of the variantList supplied by the target may depend on the implementation.
For example, for an element (representing a document) which the target provides
in PostScript, consider the following cases:
The target might list a single supportedVariant in the variant list for the element, indicating that the element is available in postScript. In that case the origin cannot necessarily conclude which of the above cases applies. The target might instead list three supportedVariants, each indicating postScript and a language. In that case, it may be reasonable for the origin to surmise that the element is available in those three languages only, but the origin probably cannot deduce which formatting parameters apply. The target might further indicate one or more formatting parameters within each supportedVariant. Again, the extent to which the origin may deduce what other variations are supported will depend on the implementation.
The origin may explicitly inquire whether a particular variant is supported, by constructing the desired variant (including all of the desired formatting parameters, etc.) and indicating "is variant supported?," using the triple (6,6, NULL). The variantRequest might also request that the target provide cost (6,1, NULL) and size (6,2, NULL) information if the variant does exist. The target would respond that the requested variant is or is not supported by supplying an appliedVariant (with the element) with the same parameters, and including the triple (7,5, TRUE or FALSE). If the target indicates TRUE (that the variant is supported) it may also supply a variantId that the origin may then use to request the variant.
The origin may construct a variantRequest that includes a variantId along with additional variant specifiers. Suppose the target lists the following supportedVariant:
(1,1, <variantId>) -- identifies this variant
(2,1, 'application/postscript') -- in postScript
(4,1, 'por') -- language: Portuguese
The element is thus available in PostScript, in Portuguese. The origin may submit a variantRequest consisting of only:
(1,1, <variantId>)
to request the element in postScript, in Portuguese.
Suppose, instead, the target lists the following supportedVariant:
(1,1, <variantId>) -- identifies this variant
(2,1, 'application/postscript') -- in postScript
Thus the target indicates that the element is available in PostScript, but no other variant information is provided.
The origin may submit a variantRequest consisting of only:
(1,1, <variantId>
(4,1 'por')
Again, this is to request the element in postScript, in Portuguese.
Or, the origin may submit the following variantRequest:
(1,1, <variantId>)
(4,1, 'por')
(4,2, 84) -- Portuguese character set
(5,3, page 1) -- begin on page 1
(5,4, page 100) -- end on page 100
to request the element in postScript, in Portuguese, Portuguese character set, pages 1-100.
RET.3.4 TagSets Defined in the
Standard
Appendix
Tag defines two tagSets, tagSet-M (for elements which convey meta- and related
information about a record) and tagSet-G (primarily for generic elements). These
two tagSets are described in RET.3.4.1 and RET.3.4.2.
RET.3.4.1 TagSet-M
TagSet-M defines
a set of elements that the target might choose to return within a retrieval
record, even though the element was not requested and in fact is not actually
information contained within the database record. Rather, it is information
about the database record, retrieval record, or result set record.
Within a GRS-1 record, the target returns tagSet-M elements in exactly the same
manner that it returns elements from any other tagSet.
TagSet-M elements fall into three categories.
RET.3.4.1.1 Meta-Information
The definitions
for these elements are provided in TAG.2.1. Any of these elements may or may
not actually occur within the database record. However, it is emphasized that
these elements describe the database record; they do not pertain to
elements within the database record which may in fact be meta-information about
some object other than the record itself.
For example, tagSet-M element 'url' refers to a URL for the database record. The database record itself may contain URLs for resources that the record describes; tagSet-M element 'url' does not pertain to those.
RET.3.4.1.2 Information about the Retrieval Record
RET.3.4.1.2.1
schemaIdentifier
A retrieval
record is meaningful only within the context of a schema definition. In many
(perhaps most) cases the target may reasonably expect that the origin knows
which schema definition applies to a particular retrieval record. In those cases
the target need not explicitly identify the schema. This element is provided
for cases where there is a possibility of uncertainty about which schema applies.
This element is also useful for retrieval records that include subordinate or nested records which are defined in terms of different schemas. See RET.3.4.1.2.5.
This element, if provided, should normally occur as the first element within the retrieval record (or within a subordinate or nested record) and for that reason is assigned tag 1, in case the target wishes to present elements in numerical order (see RET.3.4.1.2.2).
RET.3.4.1.2.2
elementsOrdered
This is
a BOOLEAN flag indicating whether the elements of the retrieval record are presented
in order by tag. The ordering is described in TAG.2.1. This element is defined
because it may be useful for an origin to know whether elements are presented
in order, when trying to locate a particular element within the retrieval record.
This element, if provided, should normally be occur as the first element within the retrieval record, or the second if schemaIdentifier is provided, and for that reason is assigned tag 2.
RET.3.4.1.2.3
elementOrdering
For a
retrieval record containing recurring elements, i.e. sibling elements with the
same tag, the target might present these elements according to some logical
order, for example, chronological, increasing generality, concentric object
snapshots, or normal consumption (i.e. pages, frames). This element indicates
the order; values are listed in TAG.2.1. Note that the values are the same as
those for seriesOrder (see RET.3.2.3.2) which applies at the element level,
i.e. it pertains to sub-elements of an element. This element, elementOrdering,
applies at the record level, i.e. it applies throughout the record, and pertains
wherever sibling elements with the same tag occur.
RET.3.4.1.2.4 Defaults (tagType,
variantSetId, and variantSpec)
defaultTagType, if provided, is
the assumed tagType for presented elements where the tagType is omitted. It
is defined solely to allow simplification of the retrieval record. If there
is a predominant tagType within the retrieval record, this meta-element allows
the target to omit the tagType for those element with that tagType.
Note that the schema may also list a default tagType. If so, then defaultTagType, if it occurs, overrides the schema-listed default. If the schema does not list a default tagType, and if this element does not occur, then every tag within the retrieval record must include a tagType.
defaultVariantSetId is the assumed variantSetId for appliedVariants within the retrieval record that omit the variantSetId. defaultVariantSpec, if provided, is the assumed appliedVariant for all elements within the retrieval for which an appliedVariant is not provided. The schema may also list a default variantSetId and/or appliedVariant. If so, then these elements if they occur, override the schema-listed default. If the schema does not list a default variantSetId and defaultVariantSetId is not provided, then every appliedVariant within the retrieval record must include a variantId. If the schema does not list a default appliedVariant and defaultVariantSpec is not provided, then for elements within the retrieval record for which an appliedVariant is not supplied, no appliedVariant is assumed to apply.
RET.3.4.1.2.5 Record
The tagSet-M element
'record' may be used to present nested or subordinate records.
A retrieval record represents a single database record, but that database record may contain elements which in turn represent database records (possibly replicated from a different database). For example, a database may contain records representing queued database updates. Each such record might contain a set of database records to be contributed to some other database. As another example, an OPAC database might have records defined to each include a bibliographic record and a corresponding holdings record, and the holdings record in turn might include a series of circulation records.
It is important to note that although a single retrieval record may include an arbitrary number of subordinate records, or arbitrarily nested records, the retrieval record nevertheless represents a single result set record.
A subordinate (or nested) record defined in this manner may be presented according to a schema different from the schema applying to the retrieval record. The tagSet-M element schemaIdentifer may be included within the element representing a record, and if so, it applies only within that element.
RET.3.4.1.2.6 wellKnown
Some schema
developers anticipate that for certain elements, different targets will want
to provide several alternative forms of the element. The element 'wellKnown'
is defined in order to support this flexibility.
Suppose a schema defines the element 'title'. The intent may be that the target simply return a single value, what the target considers to be the title. In that case, 'title' should be a leaf-node defined from tagSet-G, and 'wellKnown' does not apply.
But suppose the target wishes to return the element 'title' encompassing several forms of the title, including one which the origin will recognize to be the default in case it does not understand any of the others (in which case it may ignore all except the default, or may still display them to the end-user, who might understand them even if the origin does not). The origin returns the single element 'title', which is structured into the following sub-elements:
The additional forms of title (i.e. those other than the default title) might use the above string tags, locally defined, or they may be known tags defined in other tag sets. However, the default title has a distinguished integer tag, that assigned to the tagSet-M element wellKnown, to distinguish it.
The element wellKnown is thus always subordinate to a parent element whose semantics are known (e.g. 'title', 'address', 'name'), and the parent element is structured into one or more forms of that element, one of which is a default form, distinguished by the tag for the element wellKnown. The context of the element wellKnown is known from its parent.
RET.3.4.1.2.7 recordWrapper
This element
is defined for use in presenting a record with no root (e.g. a flat record,
or a record whose hierarchical structure is that of multiple trees). When the
origin requests this element, the request is interpreted as a request for the
entire record to be presented subordinate to this element. It is defined primarily
to be used in conjunction with a variantRequest specifying 'noData', for the
purpose of retrieving a skeleton record (i.e. tags only, no data). If a record
does have a root, then if this element occurs, the record's real root is presented
subordinate to this element.
RET.3.4.1.3 Information about Result Set
Record
TagSet-M
elements rank and score provide information pertaining to a record's entry in
the result Set. A record may have both a rank and a score.
The rank of a result set record is an integer from 1 to N, where there are N
entries in the result set (each record should have a unique rank). The score
of a result set record is an integer from 1 to M where M is the normalization
factor, which may be independent of the size of the result set, and more than
one record may have the same score. The normalization factor should be specified
in the schema.
RET.3.4.2 TagSet-G
TagSet-G includes
generic elements which may be of general use for schema definitions. They are
all self-explanatory, except perhaps the element bodyOfDisplay.
RET.3.4.2.1 bodyOfDisplay
The target
might combine several elements of a record into this single element, into a
display format, for the origin to display to the user.
For a given schema, perhaps for a particular application, some origins may need the target to distinguish all elements in a retrieval record, perhaps because the origin is going to replicate the record. In other cases, the origin is satisfied for the target to package all elements into display format for direct display to the end-user. In either of these cases, bodyOfDisplay is not applicable (in the latter case the target may use the SUTRS record syntax instead of GRS-1).
In some cases though, the origin may need some of the elements distinguished, but is satisfied to have the target package the remaining elements into a single retrieval element for display. In these cases bodyOfDisplay may be useful.
Suppose the target wishes to present 20 elements of a record, but only the first three elements are intended for origin use, and the remaining elements are intended to be transparently passed to the user. Rather than packaging all 20 elements, the target instead may send 4 elements, where the 4th delivery element packages the latter 17 original elements, in a display format.
The bodyOfDisplay element is similar to a composite element (as described in RET.3.1.2) in the fact that a single retrieval element packages multiple logical element. But bodyOfDisplay differs from a composite element in three respects:
The target, not the origin, selects the subset of elements for packaging.
In a composite element there may be semantics conveyed by the tag that the origin or user might understand. For example a request for a composite element may ask for the b subfield of the 245 field concatenated with c subfield of 246 sent back as deliveryElement called 'title' (there may be some recognizable semantics associated with the tag 'title'). The bodyOfDisplay element has no semantics other than telling the origin "here is a composite element for display."
The resultant element should always be in display format. A composite element may assume display format, but it may also assume other formats, as determined by the variant.
This appendix lists Z39.50 profiles approved by the Open Systems Environment Implementors Workshop (OIW) Special Interest Group on Library Applications (SIG/LA).
At the time of publication of this standard, the following profiles have been approved by the OIW SIG/LA:
1. GILS
Application Profile for the Government Information
Locator Service. GILS specification for ANSI/NISO Z39.50 as well as other aspects
of a GILS conformant server that are outside the scope of Z39.50. The GILS Profile
provides the specification for the overall GILS application including the GILS
core, which is a subset of all GILS locator records, and completely specifies
the use of Z39.50 in this application.
2. WAIS
WAIS Profile of Z39.50 Version 2 (Version 1.4): Application
Profile for WAIS (Wide Area Information Servers) network publishing systems.
Based on Z39.50 Version 2 as specified in ANSI/NISO Z39.50-1995.
3. ATS-1
Specifies the use of the attribute set bib-1 within
a Z39.50 type-1 query for searching by author, title, or subject, to provide
basic search access to bibliographic databases. Its purpose is to ensure that
complying origins and targets can provide basic search access to bibliographic
databases, similar to the common online catalog systems used in many libraries.
4. Using Z39.50-1992 Directly over TCP
Based on an Internet
RFC "Using the Z39.50 Information Retrieval Protocol in the Internet Environment",
this profile addresses (and its scope is limited to):
For information on how to obtain these documents, refer to: http://www.loc.gov/z3950/agency