The core information that many users want to find when they look for a business online include locations, operating hours, contact information, and branch relationships.
In this exercise, you will mark up your library, archives, museum, or other organizational home page with machine-readable address information, contact information, and opening hours using the schema.org vocabulary. You will use a library home page as your template, but the exercise should be adaptable to any kind of organization.
Audience: Beginner
Prerequisites: To
complete this codelab, you will need a basic familiarity with HTML. The
exercises can be found in codelab.zip,
with the solutions found in the rdfa_exercises subdirectory. There are
frequent checkpoints through the code lab, so if you get stuck at any point,
you can use the checkpoint file to resume and work through this codelab
at your own pace.
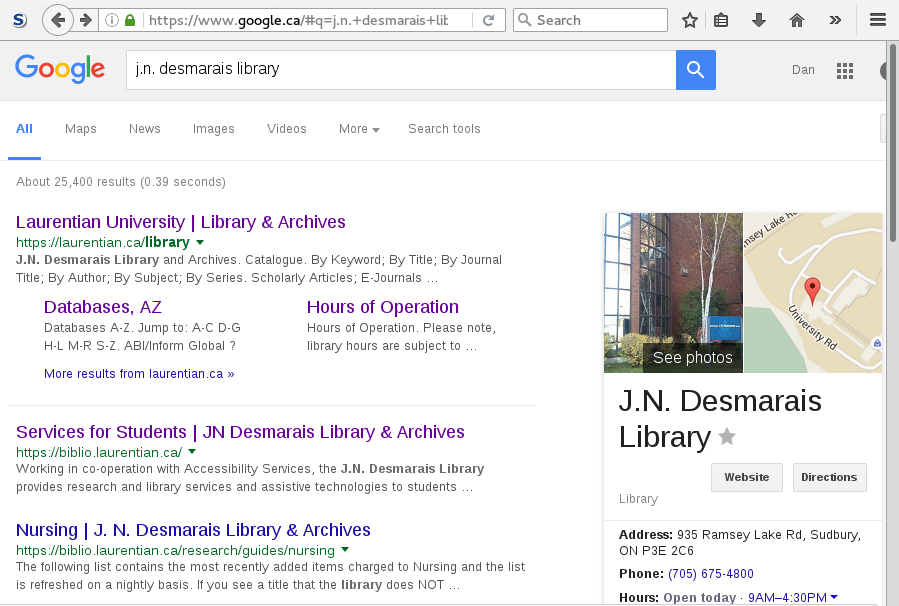
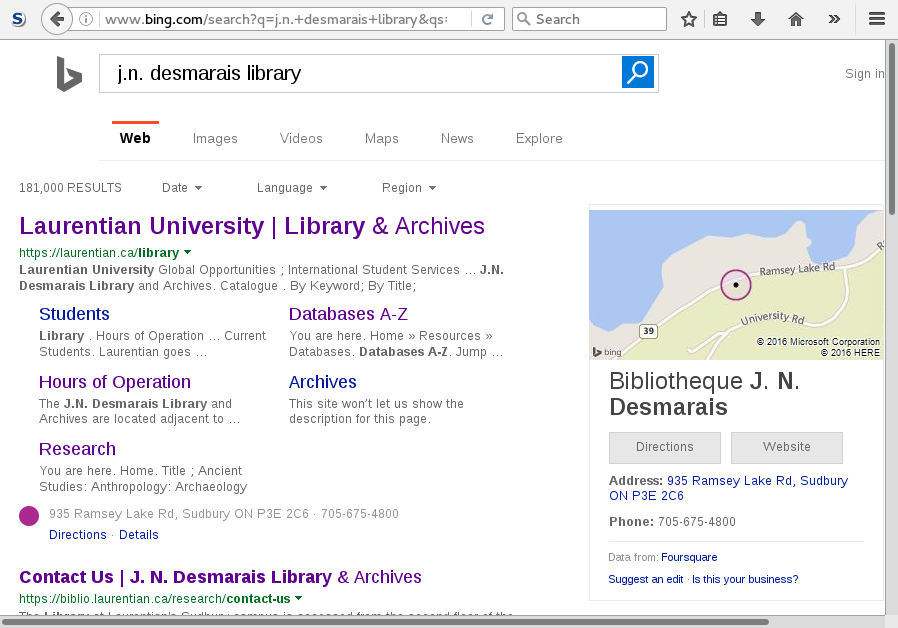
When you search for a library on different search engines, you will probably get different and conflicting sets of information about the library. The results often depend on where the information is pulled from, which in turn depends on relationships that the search engines have with various data providers. For example, compare searches for my home library J.N. Desmarais Library:
This is a sad state of affairs, and while our library certainly could work harder on outreach and search engine optimization, we are hardly alone.
Having to maintain information such as address, contact information, and hours of operation in multiple places is inefficient and error-prone. Rather than pushing information to multiple sites, it makes much more sense to allow interested sites to pull the information from one authoritative source. OCLC has positioned themselves with the OCLC Library Spotlight Program to provide this information to various commercial companies such as Yelp, but the simplest possible method would be for cultural institutions to mark up their own home pages (where that information almost certainly already exists for the benefit of human readers) with the relevant schema.org structured data so that the machines can benefit as well.
In this exercise, you will learn the basic steps required to add simple RDFa structured data to an existing organizational home page.
Open lhsmith_branch.html
in an HTML-friendly text editor such as vim, emacs, nano, Sublime,
Atom... anything but Notepad! You should see something like the
following HTML source for the web page:
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
<title>Lillian H. Smith : Toronto Public Library</title>
<meta name="description" content="Lillian H. Smith, 239 College Street, Toronto, M5T 1R5, ON, 416-393-7746" />
<meta name="keywords" content="Lillian H. Smith, 239 College Street, Toronto, M5T 1R5, ON, 416-393-7746" />
<meta name="thumbnail" content="" />
<meta name="identifier" content="http://www.torontopubliclibrary.ca/detail.jsp" />
<link rel="schema.DCTERMS" href="http://purl.org/dc/terms/" />
<meta name="DC.creator" content="" />
<meta name="DC.date.created" content="" />
<meta name="DC.date.modified" content="" />
<meta name="DC.language" content="en" />
<meta name="DC.type" content="Library Branch" />
<meta name="DC.audience" content="" />
<meta property="og:title" content="Lillian H. Smith" />
<meta property="og:type" content="landmark" />
<meta property="og:image" content="http://www.torontopubliclibrary.ca/content/branches/images/lillian-h-smith-library-01.jpg"/>
<meta property="og:description" content="Lillian H. Smith, 239 College Street, Toronto, M5T 1R5, ON, 416-393-7746"/>
<meta property="og:url" content="http://www.torontopubliclibrary.ca/detail.jsp?Entt=RDMLIB011&R=LIB011"/>
<meta property="og:site_name" content="Toronto Public Library" />
</head>
<body>
...
</body>
</html>
Note: In a pinch, you can use the browser development tools to
view and edit the source of the web page (CTRL-Shift-i in
Chrome or Firefox, in the Elements or Inspector tab
respectively).
There are a number of structured data parsers, both online and locally installable, that can help you check the results of your work. Copy and paste the HTML source into each of the following online structured data extraction tools:
Notice that the results vary between the parsers. Some of them reveal that there is, indeed, some markup already embedded in the page--but that markup is sparse:
@prefix og: <http://ogp.me/ns#> .
<http://rdfa.info/play/>
og:title "Lillian H. Smith"@en;
og:type "landmark"@en;
og:image "http://www.torontopubliclibrary.ca/content/branches/images/lillian-h-smith-library-01.jpg"@en;
og:description "Lillian H. Smith, 239 College Street, Toronto, M5T 1R5, ON, 416-393-7746"@en;
og:url "http://www.torontopubliclibrary.ca/detail.jsp?Entt=RDMLIB011&R=LIB011"@en;
og:site_name "Toronto Public Library"@en .
What you see is an example of Open Graph Protocol
markup, a vocabulary and syntax based on RDFa 1.0 developed by
Facebook and promoted as a means of embedding simple machine-readable
markup in the head section of web pages. While this is a good
start—enough to identify the title of the page and an image that can be
used in short snippets—we can surface much richer data by using RDFa 1.1
and marking up the body of the web page with the schema.org vocabulary.
RDFa (Resource Description Framework in attributes) enables you to embed descriptions of things (types) and their properties within HTML documents using just a handful of HTML attributes.
To avoid a tower of Babel situation where one person uses the type name "author" to refer to the same concept that someone else calls a "writer", collections of types and their properties are typically standardized and published as a vocabulary (also known as an ontology).
Each type and property is expected to have a dereferenceable URI so that
you (or more realistically the machines) can look up the definition of
the vocabulary element and determine its relationship (if any) to other
vocabulary elements. For example, you can look up
http://schema.org/Book
and learn that it is a subclass of the Thing / CreativeWork
hierarchy.
You could use the full URI for each vocabulary element, but that would
be extremely verbose - especially given vocabularies that publish URIs
like http://rdaregistry.info/Elements/a/countryAssociatedWithThePerson.
Therefore, RDFa offers the @vocab attribute; if you
add a vocab="http://<path/for/vocab>"
attribute to an HTML element, any of the RDFa @typeof and
@property attributes within its scope will automatically
prepend the specified value to those attributes.
You are going to use the schema.org vocabulary for your exercise, as it
includes types and properties that enable you to describe many things of
general interest without having to mix and match multiple vocabularies.
Declare the default vocabulary for the HTML document
as http://schema.org/ on the <body>
element.
Note: Do not forget the trailing slash (/)!
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
...
</head>
<body vocab="http://schema.org/">
...
</body>
</html>Many vocabularies focus on a particular domain; for example:
In practice, documents often ended up using types and properties from several different vocabularies. While vocabulary description languages like RDF Schema (RDFS) and the Web Ontology Language (OWL) offer ways to express equivalence between types and properties of different vocabularies, it can still be extremely complex to publish and consume mixed-vocabulary documents.
schema.org, on the other hand, tries to provide a vocabulary that can describe almost everything, albeit in many cases with less granularity than more specialized vocabularies.
Unless declared otherwise, web pages are assumed to have a type of WebPage. The choice of type is important as it dictates which properties you can "legally" use, so this section will help you find a more specific match for your purposes.
The schema.org types are arranged in a top-down hierarchy. Starting at
the top level of the type
hierarchy, browse through the Organization
type hierarchy. Notice how each type inherits the properties from its parent
(beginning with Thing), offers its own more specific definition
for its raison d'etre, and may add its own properties to enable you
to describe it more completely.
For libraries, schema.org models this information in the Organization -> LocalBusiness -> Library hierarchy.
For museums, schema.org models this information in the Place -> CivicStructure -> Museum hierarchy.
For archives, no Archive type currently exists in the official
schema.org vocabulary, but a working group has proposed an
extension for Archives. In the interim, you can use the proposed
Archive
type—but you should also include a more generic official type (LocalBusiness) to help
parsers fall back to the semantics of the more general type.
To declare an RDFa type for an HTML document, add the
@typeof attribute to the <body> element
and set the value of the attribute to Library.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
...
</head>
<body vocab="http://schema.org/" typeof="Library">
...
</body>
</html>
Note: If you are marking up an Archive but want to include the fallback
generic type, RDFa allows you to specify lists of properties or
types in a single attribute by separating them with a space. In this
case, that looks like typeof="LocalBusiness
http://archive.sdo-archive.appspot.com/Archive".
Every schema.org type has a name property available to it, because the
property is declared on the Thing type from which every other type
inherits. Add a @property="name"
attribute to the <h1> element to assert that
the content of that element is the name of the library branch.
Note: You might be tempted to add the attribute to the
<title> element of the HTML document, but this would
fall outside of the scope of your @typeof attribute. A
search engine can infer that if the content of the
<title> and <h1> for a given web
page match, then the <h1> likely the title; but your
explicit assertion of that property is stronger than an inference.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
<!-- ... -->
</head>
<body vocab="http://schema.org/" typeof="Library">
...
<div id="branch-detail">
<h1 property="name">Lillian H. Smith</h1>
...
</body>
</html>Check the results with one or more of the structured data testing tools to ensure the type and name are correctly recognized.
image, description, and logo propertiesAs most schema.org types inherit from Thing, some of the core properties used on almost every type are name, image, description, and logo. These properties are often used to generate rich snippets (short summaries displayed in search results).
You have already declared the name of this organization. The
image should be a representative picture of the subject you are
describing, while the description should be "[a] short
description of the item", and the logo should be an image that
represents the brand of the organization. Mark up the image,
description, and logo properties for this library.
Suggestion: As this page does not contain a good one or
two-sentence description, go ahead and declare the entire
Features section as the description.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
<!-- ... -->
</head>
<body vocab="http://schema.org/" typeof="Library">
...
<div id="logo-item" >
<a href="http://www.torontopubliclibrary.ca/"><img
alt="Toronto Public Library Homepage"
property="logo"
src="images/tpl-logo.png"/></a>
</div>
...
<div id="branch-detail">
<h1 property="name">Lillian H. Smith</h1>
...
<div>
<div id="detail-image-container">
<img id="detail-image" src="images/lillian-h-smith-library-01.jpg"
property="image" />
</div>
</div>
...
<div id="tab3" property="description">
<h2>Features</h2>
...
</div>
...
</div>
</body>
</html>
Check your results of your markup using one of the suggested tools.
If you found that your logo was associated with a
different URL, you've discovered one of the complications of RDFa. An
<a> element that does not contain a
@property attribute associates any of the properties within
its scope to the subject defined by its @href attribute.
To associate the logo with the Library subject that you are
describing for this particular branch, you can use the
@about attribute to explicitly identify the subject to
which a given property belongs. The value of the @about
attribute can be any URL, enabling you to make an assertion about any
subject on the web, but you will most often use a fragment identifier
(a hashURI) to annotate a type that you have identified using
a corresponding @resource attribute.
A subject that does not have a specific identifier is called a
blank node, and while it can provide useful information
within the broader context of the linked data in which it is embedded,
it cannot be directly and reliably addressed due to the lack of an
identifier. Every time you add a @typeof attribute, you
should strongly consider adding a @resource attribute to
explicitly identify it. This enables you, and anyone else in the linked
data world, to easily retrieve and make assertions about your very
granular linked data subjects.
In the <body> element of the page, add a
@resource="#library" attribute to uniquely identify it,
alongside the @typeof="Library" attribute you added
earlier. Then add the @about="#library" attribute to the
@property="logo" assertion you just made, and check the
difference that makes to the parser output.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
<!-- ... -->
</head>
<body vocab="http://schema.org/" typeof="Library" resource="#library">
...
<div id="logo-item" >
<a href="http://www.torontopubliclibrary.ca/"><img
alt="Toronto Public Library Homepage"
property="logo" about="#library"
src="images/tpl-logo.png"/></a>
</div>
...
<div id="branch-detail">
<h1 property="name">Lillian H. Smith</h1>
...
<div>
<div id="detail-image-container">
<img id="detail-image" src="images/lillian-h-smith-library-01.jpg"
property="image" />
</div>
</div>
...
<div id="tab3" property="description">
<h2>Features</h2>
...
</div>
...
</div>
</body>
</html>
Identifying the address for the branch helps consuming applications provide
a geographic context for their users. For example, the application could
order search results based on proximity to the searcher's own geolocation.
The Organization
type from which Library inherits includes a address property for this
purpose.
Identifying the phone number for an organization makes it easier for users to contact your organization. The Organization type includes a telephone property for this.
Mark up the address and telephone properties for this branch.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
<!-- ... -->
</head>
<body vocab="http://schema.org/" typeof="Library" resource="#library">
...
<div id="branch-detail">
<h1 property="name">Lillian H. Smith</h1>
<div>
<div>
<h4>Location</h4>
<div>
<p property="address">239 College Street, Toronto, ON <br/>
M5T 1R5
</p>
<div property="telephone">
<a id="branch-phone"></a>
416-393-7746
</div>
</div>
</div>
</div>
...
<div>
<div id="detail-image-container">
<img id="detail-image" src="images/lillian-h-smith-library-01.jpg"
property="image" />
</div>
</div>
...
<div id="tab3" property="description">
<h2>Features</h2>
...
</div>
...
</div>
</body>
</html>
Check the documentation for the Organization.
Notice that while the address property can accept simple
Text as its value,
it can also accept a more structured PostalAddress
subject for its value. PostalAddress types can include
the following properties:
addressCountryaddressLocalityaddressRegionpostOfficeBoxNumberpostalCodestreetAddress
By breaking out the content of the address into separate properties using
<span> elements, you can provide much more granular information
to the processors of this data, and spare them from having to parse out
the different segments of the address (perhaps incorrectly).
Add the @typeof="PostalAddress" attribute to the element
where you previously identified the address, then break out the
content of the address into more granular properties.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
<!-- ... -->
</head>
<body vocab="http://schema.org/" typeof="Library" resource="#library">
...
<div id="branch-detail">
<h1 property="name">Lillian H. Smith</h1>
<div>
<div>
<h4>Location</h4>
<div>
<p property="address" typeof="PostalAddress">
<span property="streetAddress">239 College Street</span>,
<span property="addressLocality">Toronto</span>,
<span property="addressRegion">ON</span> <br/>
<span property="postalCode">M5T 1R5</span>
</p>
<div property="telephone">
<a id="branch-phone"></a>
416-393-7746
</div>
</div>
</div>
</div>
...
<div>
<div id="detail-image-container">
<img id="detail-image" src="images/lillian-h-smith-library-01.jpg"
property="image" />
</div>
</div>
...
<div id="tab3" property="description">
<h2>Features</h2>
...
</div>
...
</div>
</body>
</html>Operating hours are one of the most frequently consulted pieces of information for any organization. The schema.org vocabulary provides two different ways of marking up operating hours. In this exercise, you will use the more structured openingHoursSpecification (which was derived from the GoodRelations vocabulary) instead of the similarly named but less structured openingHours.
The openingHoursSpecification property expects a OpeningHoursSpecification
type, which is composed of the following properties:
closeshh:mm:ss[Z|(+|-)hh:mm] format.dayOfWeek| Day | Value |
|---|---|
| Monday | http://purl.org/goodrelations/v1#Monday |
| Tuesday | http://purl.org/goodrelations/v1#Tuesday |
| Wednesday | http://purl.org/goodrelations/v1#Wednesday |
| Thursday | http://purl.org/goodrelations/v1#Thursday |
| Friday | http://purl.org/goodrelations/v1#Friday |
| Saturday | http://purl.org/goodrelations/v1#Saturday |
| Sunday | http://purl.org/goodrelations/v1#Sunday |
| Public holidays | http://purl.org/goodrelations/v1#PublicHolidays |
openshh:mm:ss[Z|(+|-)hh:mm] format.validFromvalidThrough
Given this information, mark up the operating hours for this branch. Note
that the human-oriented hours do not satisfy the requirements for the
closes and opens properties, so you should use
the @content attribute to provide the machine-readable version
of the information.
Bonus points: Also mark up the dates for which the indicated Sunday hours are valid.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
<!-- ... -->
</head>
<body vocab="http://schema.org/" typeof="Library" resource="#library">
...
<div id="branch-detail">
<h1 property="name">Lillian H. Smith</h1>
...
<table cellspacing="0" summary="Opening and closing hours for this branch.">
<colgroup>
<col width="10%" />
<col />
</colgroup>
<tfoot>
<tr><td colspan="3">*Sunday hours in effect from September to June
<time property="validFrom" datetime="2015-09-01" about="#sundayHours" />
<time property="validThrough" datetime="2016-06-01" about="#sundayHours" />
</td>
</tr>
</tfoot>
<tbody>
<tr><caption>Branch Hours</caption></tr>
<tr>
<th colspan="1">Day</th>
<th colspan="1">Opening Time</th>
<th colspan="1">Closing Time</th>
</tr>
<tr property="openingHoursSpecification" typeof="OpeningHoursSpecification">
<th class="days" scope="row" property="dayOfWeek"
href="http://purl.org/goodrelations/v1#Monday">Monday</th>
<td class="hours" property="opens" content="09:00:00">9:00 a.m.</td>
<td property="closes" content="20:30:00">8:30 p.m.</td>
</tr>
<tr property="openingHoursSpecification" typeof="OpeningHoursSpecification">
<th class="days" scope="row" property="dayOfWeek"
href="http://purl.org/goodrelations/v1#Tuesday">Tuesday</th>
<td class="hours" property="opens" content="09:00:00">9:00 a.m.</td>
<td property="closes" content="20:30:00">8:30 p.m.</td>
<td class="hours">9:00 a.m.</td>
<td>8:30 p.m.</td>
</tr>
<tr property="openingHoursSpecification" typeof="OpeningHoursSpecification">
<th class="days" scope="row" property="dayOfWeek"
href="http://purl.org/goodrelations/v1#Wednesday">Wednesday</th>
<td class="hours" property="opens" content="09:00:00">9:00 a.m.</td>
<td property="closes" content="20:30:00">8:30 p.m.</td>
<td class="hours">9:00 a.m.</td>
<td>8:30 p.m.</td>
</tr>
<tr property="openingHoursSpecification" typeof="OpeningHoursSpecification">
<th class="days" scope="row" property="dayOfWeek"
href="http://purl.org/goodrelations/v1#Thursday">Thursday</th>
<td class="hours" property="opens" content="09:00:00">9:00 a.m.</td>
<td property="closes" content="20:30:00">8:30 p.m.</td>
<td class="hours">9:00 a.m.</td>
<td>8:30 p.m.</td>
</tr>
<tr property="openingHoursSpecification" typeof="OpeningHoursSpecification">
<th class="days" scope="row" property="dayOfWeek"
href="http://purl.org/goodrelations/v1#Friday">Friday</th>
<td class="hours" property="opens" content="09:00:00">9:00 a.m.</td>
<td property="closes" content="20:30:00">8:30 p.m.</td>
<td class="hours">9:00 a.m.</td>
<td>8:30 p.m.</td>
</tr>
<tr property="openingHoursSpecification" typeof="OpeningHoursSpecification">
<th class="days" scope="row" property="dayOfWeek"
href="http://purl.org/goodrelations/v1#Saturday">Saturday</th>
<td class="hours" property="opens" content="09:00:00">9:00 a.m.</td>
<td property="closes" content="17:00:00">5:00 p.m.</td>
</tr>
<tr property="openingHoursSpecification" typeof="OpeningHoursSpecification"
resource="#sundayHours">
<th class="days" scope="row" property="dayOfWeek"
href="http://purl.org/goodrelations/v1#Sunday">Sunday</th>
<td class="hours" property="opens" content="13:30:00">1:30 p.m.</td>
<td property="closes" content="17:00:00">5:00 p.m.</td>
</tr>
</tbody>
</table>
...
</body>
</html>Many organizations are a part of a larger organization. For example, a library branch may be part of a public library system, or an archive might be part of a university or municipality. You can use the parentOrganization property to identify the parent of the organization you are describing.
In this example, the parent organization of the branch you are describing
is the Toronto Public Library (TPL), and a link to the TPL home page is
included at the top of the page. Mark up the corresponding
<a> element with the parentOrganization
property.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf8" />
<!-- ... -->
</head>
<body vocab="http://schema.org/" typeof="Library" resource="#library">
<div id="header-container">
<div>
<div>
<div id="logo-item" >
<a href="http://www.torontopubliclibrary.ca/"
property="parentOrganization"><img
alt="Toronto Public Library Homepage"
property="logo" about="#library"
src="images/tpl-logo.png"/></a>
</div>
...
<div id="branch-detail">
<h1 property="name">Lillian H. Smith</h1>
...
</body>
</html>Checkpoint: Your original HTML library branch page should now look like lhsmith_branch_check.html.
In this exercise, you learned how to express locations, operating hours, contact information, and organizational structure for a library branch. More generally, you learned:
@resource attributeNext codelab: Books
Dan Scott is a systems librarian at Laurentian University.

This work
is licensed under a Creative
Commons Attribution-ShareAlike 4.0 International License.